PoC: Add Qualcomm mobile SoC native backend for GGML #121
Comments
|
breakdown task(gradual refinement through Agile method and any help(from AI expert, from upstream GGML community, from Qualcomm, ......) are both greatly welcomed. Guidance from domain-expert is greatly appreciated if there is a problem in path/direction of breakdown task):
|




|
updated on 03-30-2024,19:14, PoC-S21 & PoC-S22 done did NOT touch anything core stuff in this commit just an integration/troubleshooting work. challenge might be happened in next step.
|

build skeletion of stage-2 of PoC:#121
build skeletion of stage-2 of PoC:#121
|
updated on 03-31-2024,20:21, PoC-S23 & PoC-S25 done did NOT touch anything core stuff in this commit just an integration work. challenge might be happened in next step.
|

build code skeleton of stage-2 of PoC:#121
|
updated on 04-03-2024,20:38 blocked on PoC-S26:offload simple f32 2x2 matrix addition operation to QNN CPU backend. external help from domain expert is greatly welcomed and appreciated. updated on 04-02-204, domain technical expert from Qualcomm: @quic, updated on 04-03-2024, domain technical expert from Qualcomm: I'm sorry to interrupt you, could you help take a look? this is an Android turn-key project on Qualcomm SoC based Android phone(Xiaomi 14 --- Snapdragon 8 Gen 3 --- is preferred) and easily to reproduce the issue. thanks so much. my output/progress on 04/01/2024 - 04/03/2024 could be found here, FYI: https://github.com/zhouwg/kantv/blob/kantv-poc-with-qnn/core/ggml/jni/ggml-qnn.cpp
|

|
In general I suggest to ask questions on Qualcomm forum. Instead of using QNN APIs directly, I suggest to consider SNPE, QNN TFLiteDelegate, onnxruntime-qnn-ep or Executorch. |
Appreciate too much for your help and guidance. I'm an individual freelancer Android system software programmer(not a company employee) and want to adding Qualcomm backend for GGML for personal interest or purpose of study. The background of this POC could be found at the beginning of this page. GGML is a compact(without much encapsulation) and powerful machine learning library for machine learning beginners and C/C++ programmers which come from open source community . There is no Qualcomm's official backend for GGML currently, so QNN SDK is preferred for this PoC because QNN SDK is a very low-level userspace API without much encapsulation and it's API is stable. This PoC already referenced a lot from Executorch and QNN sample: https://github.com/zhouwg/kantv/blob/kantv-poc-with-qnn/core/ggml/jni/ggml-qnn.cpp#L8 |
I see. Thank you for interest in QNN. I assume you have QNN SDK and documents. Instead of compiling out a binary, you will see a However, I don't really recommend to reference ExecuTorch codes here... Executorch is in Python and it has quite a few interesting properties, which buries QNN quite deeply. (At least they can distract you from what is the real QNN part.) Instead of ExecuTorch, I recommend to learn QNN APIs by QNN Converter plus the Saver backend mentioned above. |
|
@chiwwang, thanks for your time and appreciate so much for your guidance. your guidance is really helpful. I got the point, now the QNN pipeline works. thanks so much. words can not express my sincerely thanks for great help from you.
there is another issue:I don't know why compute result is incorrect. https://github.com/zhouwg/kantv/blob/kantv-poc-with-qnn/core/ggml/jni/ggml-qnn.cpp#L2650 |

|
@chiwwang, thanks so much for your great help and guidance again. I think I understand a little bit more about the QNN SDK and what's the tensor and what's the computation graph at the moment. your guidance is very important for this progress. now PoC-S26 finished: offload a simple f32 2x2 matrix to QNN CPU backend. it's a really milestone in this PoC. this is a workaround method, not perfect(this method is a very straight way(just like the great GGML --- without much encapsulation compare to other famous/huge machine learning framework/library) and will be used in PoCS42---PoCS44, but there are some unsolved problems in function qnn_matrix, so I think it's NOT perfect in this commit).
|

|
updated on 04-08-2024(April-08-2024) with this commit: PoC-S27 finished: offload a simple f32 2x2 matrix addition operation to QNN GPU backend(thanks to the highly well-designed QNN SDK from Qualcomm) PoC-S29&S30&32&33 finished: mapping ggml_tensor with add/mul/mulmat operation to QNN tensor with QNN CPU/GPU backend
|







|
updated on 04-09-2024, a minor refinement:
|



|
updated on 04-10-2024, a minor refinement: now the APK could works well/running well on any mainstream Qualcomm mobile SoC base Android phone, NOT limited on Xiaomi 14 or Qualcomm Snapdragon 8 Gen 3 SoC based Android phone. (the below test phone is Xiaomi 14 which contains a Qualcomm's high-end Snapdragon 8 Gen 3 mobile SoC) (the price of below test phone is about RMB 800-1200 (or USD 120 - 166, the price was RMB 1200 when I purchased it) which contains a Qualcomm's low-end mobile SoC. there is a minor UI adjustment because of screen width and height is not enough on this test phone)
|



|
i am interested in your project , and I base in Shanghai, how can I reach you ? |
thanks so much for your interesting in this AI learning project. this AI learning project focus on/powered by GGML(pls refer to background introduction of this PoC to get the reason) and focus on three heavyweight AI applications on Android device: whisper.cpp, llama.cpp, stablediffusion.cpp and try to uniform them to an ONE AI application(this project). there are some tasks in to-do list currently:
Xiaomi 14 or other Qualcomm Snapdragon 8 Gen 3 SoC based Android phone is preferred for this PoC or this AI learning project. thanks again. |
|
No description provided. |
|
No description provided. |
Summary of this PoC
Todo(improve the quality of Qualcomm QNN backend for GGML)
Highlights in 2nd milestonea complicated computation graph using QNN API(a reverse engineering implementation by Project KanTV)
(1)data path of GGML's QNN(CPU&GPU) backend (only support GGML_OP_ADD,GGML_OP_MUL, GGML_OP_MUL_MAT) works fine/well as expected with whisper.cpp on Qualcomm's SoC based Android phone(from low-end to high-end, or from RMB 800 - RMB 8000 , or from USD 110 - USD 1100). (2)data path of GGML's QNN (CPU&GPU& HTP(aka DSP) backend(only support GGML_OP_ADD, GGML_OP_MUL, GGML_OP_MUL_MAT) works fine/well as expected with whisper.cpp on Qualcomm's SoC based high-end phone(Xiaomi 14). (3)data path of GGML's QNN (CPU&GPU& HTP(aka DSP) backend(only support GGML_OP_ADD, GGML_OP_MUL, GGML_OP_MUL_MAT) works fine/well as expected with llama.cpp on Qualcomm's SoC based high-end phone(Xiaomi 14). in other words, it's a real Qualcomm's QNN backend of GGML although it's not perfect.
a simple UT framework(so-called) was added for PoC-S49:implementation of other GGML OPs using QNN API
4x performance gains for GGML_OP_MUL_MAT using QNN CPU backend with 1 thread on a Qualcomm mobile SoC based high-end Android phone(Xiaomi 14)
Acknowledgementsthanks to the great/breakthrough help from @chiwwang(a technical expert from Qualcomm), thanks to the highly well-designed Qualcomm's QNN SDK(I personally think it's really match with GGML), thanks to the excellent implementation of Intel SYCL backend of GGML(I really learned a lot from this implementation which come from a great open-mind company)... so this PoC could be done from 03-29-2024 to 04-22-2024 --- something I did not expect at all at the very beginning of this PoC. at the end of this section, I'd like to express my sincerely thanks to the original author(authors) of the great GGML/whisper.cpp because I'm a real AI beginner and learned a lot of interesting things from these two great open-source C/C++ AI projects. all the source codes(no any reserved in local) in this PoC could be found at branch "kantv-poc-with-qnn" and hope it's a little useful/helpful for programmers like me(know nothing about real AI tech)because I'm an elder programmer who does not belong to this great era/2020s. the codes of this PoC will be merged to master branch in next few days because I think it's stable enough to be merged into master branch. header file of implementation of Qualcomm's QNN backend of GGML |
















|
高手,在高通8gen3上,llama2-7B推理性能如何? 多少token/s ? |
谢谢。 性能不错,大概20 tokens/s,这还没有用到高通的硬件AI加速引擎。 anyway,衷心希望高通亲自下场类似Intel那样投人投钱投资源做SYCL后端一样做QNN后端:这样大家都省心了,直接拿来用就可以了。 感谢天才程序员Georgi Gerganov 为程序员为人类带来了GGML(同时感谢设计精巧的ggml backend subsystem的作者,虽然对其某些似乎固执的决策有所保留,但其设计精巧的backend subsystem给一个不懂硬核AI技术的我有了一点点发挥的空间)。Georgi Gerganov的确是自70后(公开资料)FFmpeg原始作者Fabrice Bellard之后的又一位来自欧洲的充满理想主义精神的90后(推测)天才程序员。 |
|
Llama 7b 有20token 太棒了! 使用llama.cpp在8gen3的cpu上4线程推理llama2-7B最多只有5token |
您的数据没问题,之前是我记错了,向您致歉。
Google的gemma在小米14上可以跑到20 tokens/s,纯CPU,没有用到高通后端,贴一幅4月24日的截图供参考。
目前的QNN后端只是一个基本雏形(data path跑通了),在小米14上whisper.cpp的测试性能赶不上纯CPU推理。个人的理解:高通花费了很大力气构建的QNN(aka AI Direct) SDK是AI时代高通平台上的闭源FFmpeg,需要程序员花费精力去研究如何正确高效的使用以充分发挥高通平台各个计算单元(异构多核)的硬件加速能力。本来打算再接再厉花费精力将ggml的QNN后端不断完善在社区的共同努力下最终接近产品质量的。anyway, I don't care it(whether the PR be approved by upstream community although I hope it becomes true) at the moment. |


{kind=link}
|
敬佩! |
谢谢。贵公司还有您个人的几个开源项目做的非常好。 |
5月份开始认真学习ncnn后才发现您是腾讯的高级研究员与工业界大名鼎鼎的AI专家。 的确太孤陋寡闻了:ncnn 2017年就开源了,2024年4月底才偶然看到。 这个AI学习项目使用/复用/参考了您的很多ncnn相关example代码,非常感谢! |
Background of this PoC:
1.GGML is a very compact/highly optimization pure C/C++ machine learning library. GGML is also the solid cornerstone of the amazing whisper.cpp and the magic llama.cpp. Compared to some well-known machine learning frameworks/libraries (e.g. Google TensorFlow, Microsoft ONNX, Meta PyTorch, Baidu PaddlePaddle......), GGML does not have much/complex/complicated/redundant/… encapsulation, so it's very very very useful/helpful/educational for AI beginner(such as me). In general, GGML has following features:
There are four "killer/heavyweight" AI applications based on GGML:
There are also some open source C/C++ open source AI projects/examples based on GGML:
Xiaomi 14 was released in China on 10-26-2023 by one of China’s largest mobile phone giants, Xiaomi 14 was available in Euro since 02-25-2024. Xiaomi 14 contains a very very very powerful mobile SoC------Qualcomm SM8650-AB Snapdragon 8 Gen 3 (4 nm).
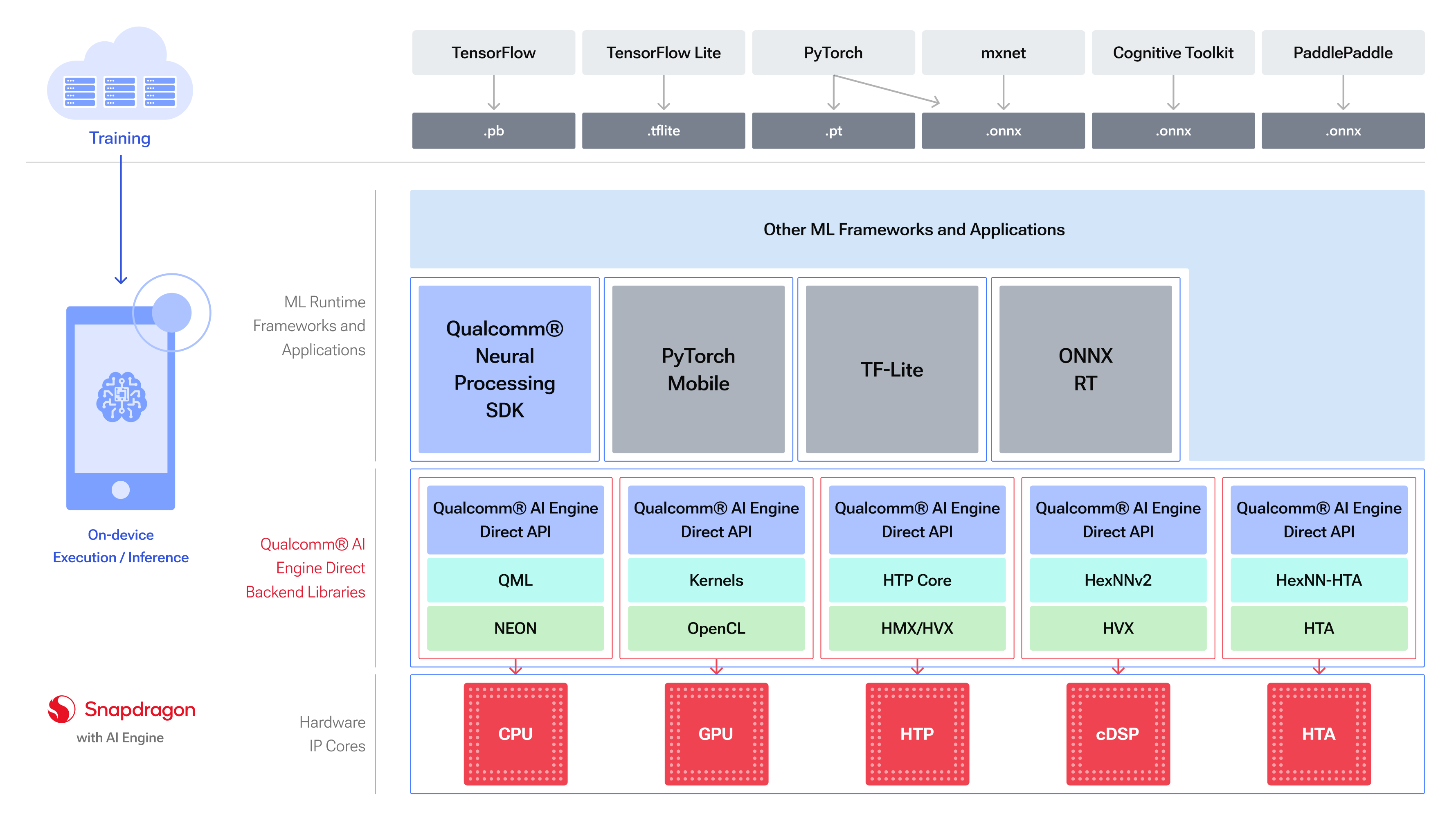
Qualcomm is No.1 mobile SoC semiconductor company in our planet currently(MediaTek's market share is No.1 in Q1 2024 but I personally think Qualcomm is the real No.1 mobile SoC vendor in our planet). QNN(Qualcomm Neural Network, aka Qualcomm AI Engine Direct) SDK is verified to work with the following versions of the ML frameworks:
after finished PoC PoC:clean-room implementation of real-time AI subtitle for English online-TV(OTT TV) #64 successfully from 03-05-2024 to 03-16-2024 (planned to complete within a week but failed. this PoC also proves GGML is really a very very very powerful/compact machine learning library and can be used in real application or real complicated scenario on mobile/edge device)
after spent 3 days(from 03-26-2024 to 03-28-2024) on llama.cpp
I want to add Qualcomm mobile SoC native backend for GGML for personal interest or purpose of study AI/machine learning( and study internal mechanism of GGML).
This PoC is a much more difficult task for me because it's my first time using Qualcomm QNN SDK and I don't know anything about real/hardcore AI /machine learning tech.
I'm not sure I can do it this time but I just want to try(and practice my C/C++ programming and troubleshooting skill). so there is NO timeline in this PoC(might be break at any point in the future).
Adding Native Support of SYCL for Intel GPUs ggerganov/llama.cpp#4749
SYCL backend support Multi-card ggerganov/llama.cpp#5282
so the integration work of SYCL will provide a huge/significant reference for this POC:we can learn something from what the Intel R&D team has done with ggml-sycl(ggml-sycl.h, ggml-sycl.cpp).
All codes in this PoC will be open-sourced in this project and want to be submitted to upstream GGML community as ggml-qnn.h&ggml-qnn.cpp if it's considered or accepted.
The text was updated successfully, but these errors were encountered: