![]()


![]()
Dagu is a powerful Cron alternative that comes with a Web UI. It allows you to define dependencies between commands as a Directed Acyclic Graph (DAG) in a declarative YAML format. Dagu simplifies the management and execution of complex workflows. It natively supports running Docker containers, making HTTP requests, and executing commands over SSH.
- Single binary file installation
- Declarative YAML format for defining DAGs
- Web UI for visually managing, rerunning, and monitoring pipelines
- Use existing programs without any modification
- Self-contained, with no need for a DBMS
- Highlights
- Table of Contents
- Features
- Use Cases
- Web UI
- Installation
- Quick Start Guide
- CLI
- Localized Documentation
- Documentation
- Running as a daemon
- Example DAG
- Motivation
- Why Not Use an Existing DAG Scheduler Like Airflow?
- How It Works
- License
- Support and Community
- Web User Interface
- Command Line Interface (CLI) with several commands for running and managing DAGs
- YAML format for defining DAGs, with support for various features including:
- Execution of custom code snippets
- Parameters
- Command substitution
- Conditional logic
- Redirection of stdout and stderr
- Lifecycle hooks
- Repeating task
- Automatic retry
- Executors for running different types of tasks:
- Running arbitrary Docker containers
- Making HTTP requests
- Sending emails
- Running jq command
- Executing remote commands via SSH
- Email notification
- Scheduling with Cron expressions
- REST API Interface
- Basic Authentication over HTTPS
- Data Pipeline Automation: Schedule ETL tasks for data processing and centralization.
- Infrastructure Monitoring: Periodically check infrastructure components with HTTP requests or SSH commands.
- Automated Reporting: Generate and send periodic reports via email.
- Batch Processing: Schedule batch jobs for tasks like data cleansing or model training.
- Task Dependency Management: Manage complex workflows with interdependent tasks.
- Microservices Orchestration: Define and manage dependencies between microservices.
- CI/CD Integration: Automate code deployment, testing, and environment updates.
- Alerting System: Create notifications based on specific triggers or conditions.
- Custom Task Automation: Define and schedule custom tasks using code snippets.
It shows the real-time status, logs, and DAG configurations. You can edit DAG configurations on a browser.
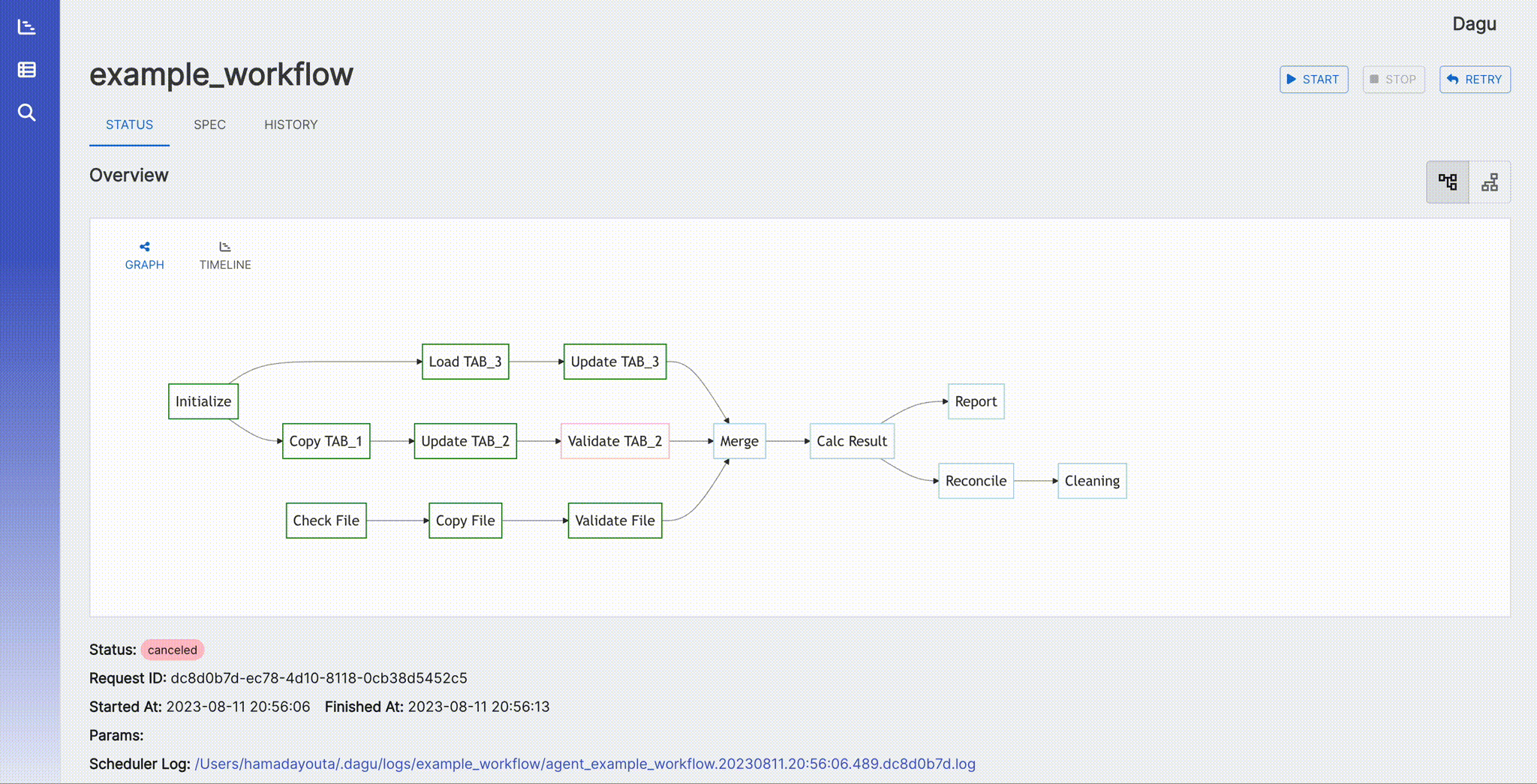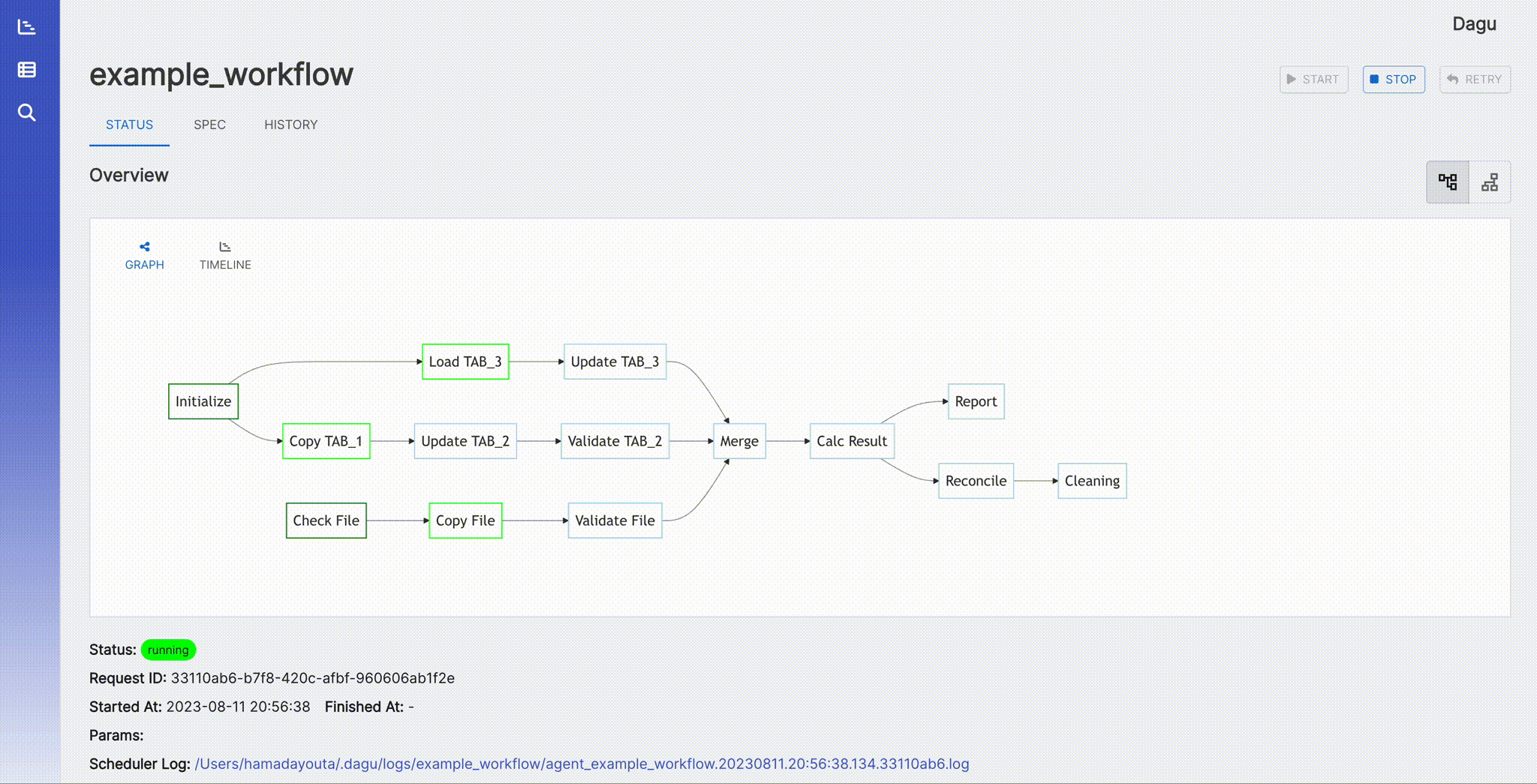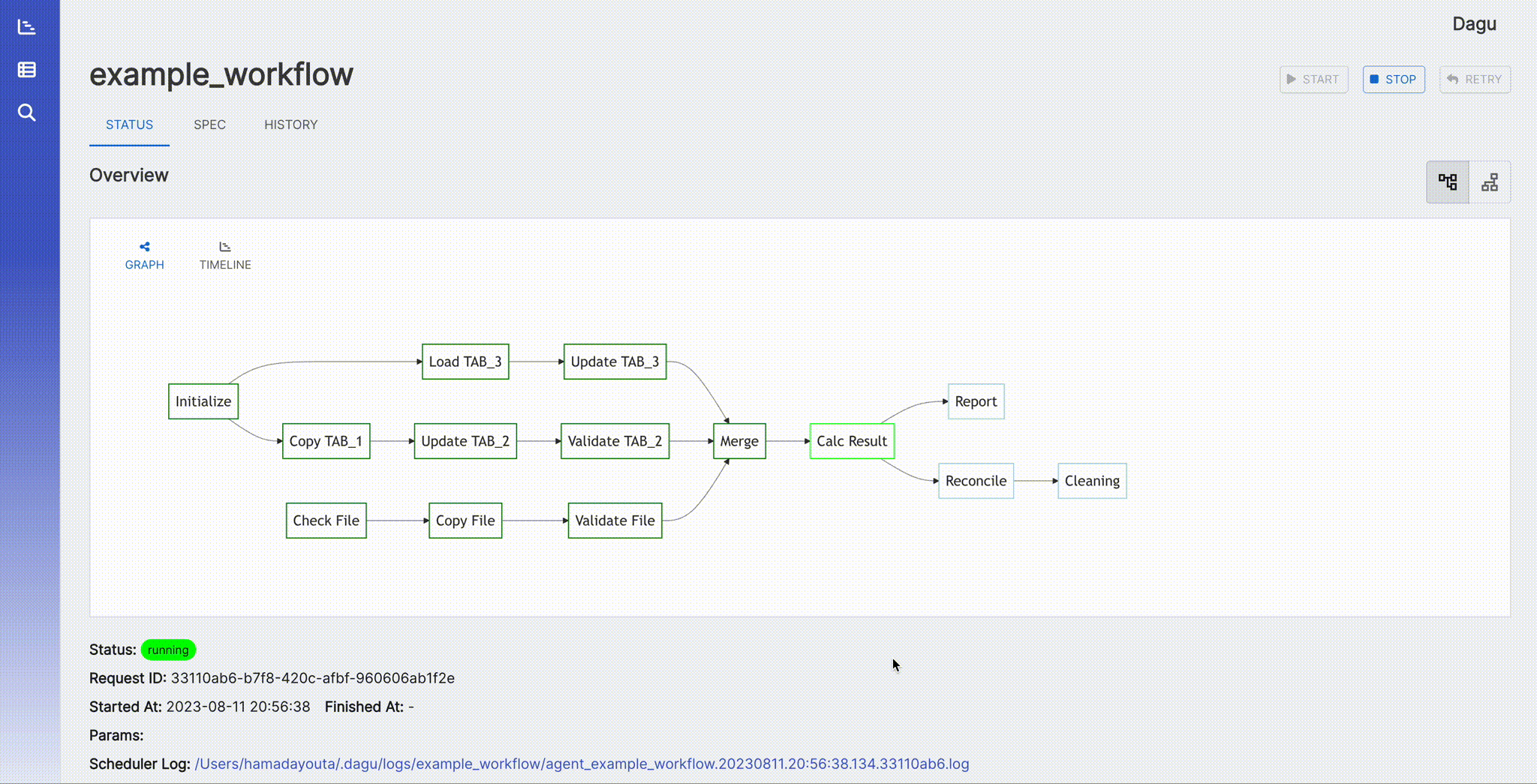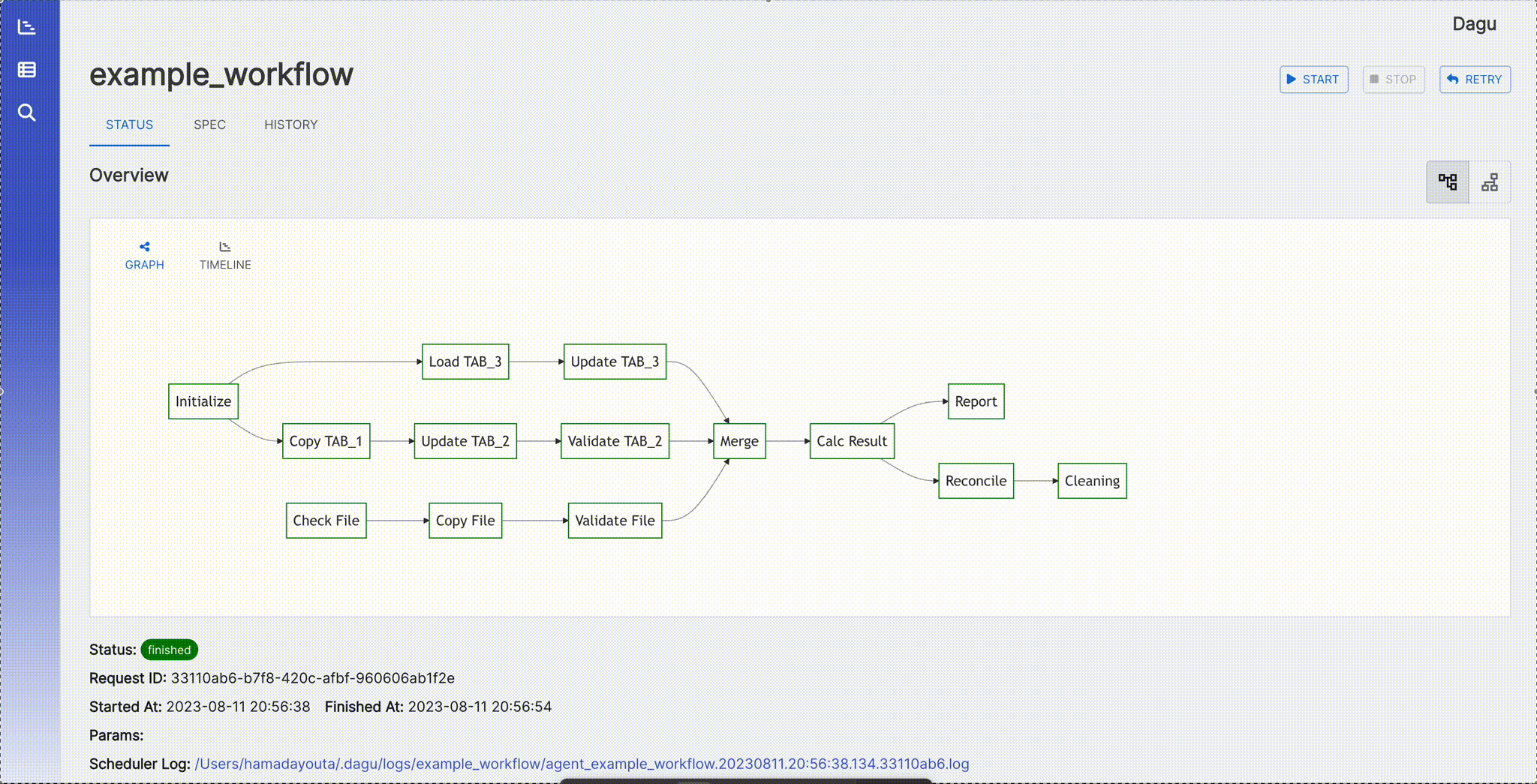
You can switch to the vertical graph with the button on the top right corner.

It shows all DAGs and the real-time status.
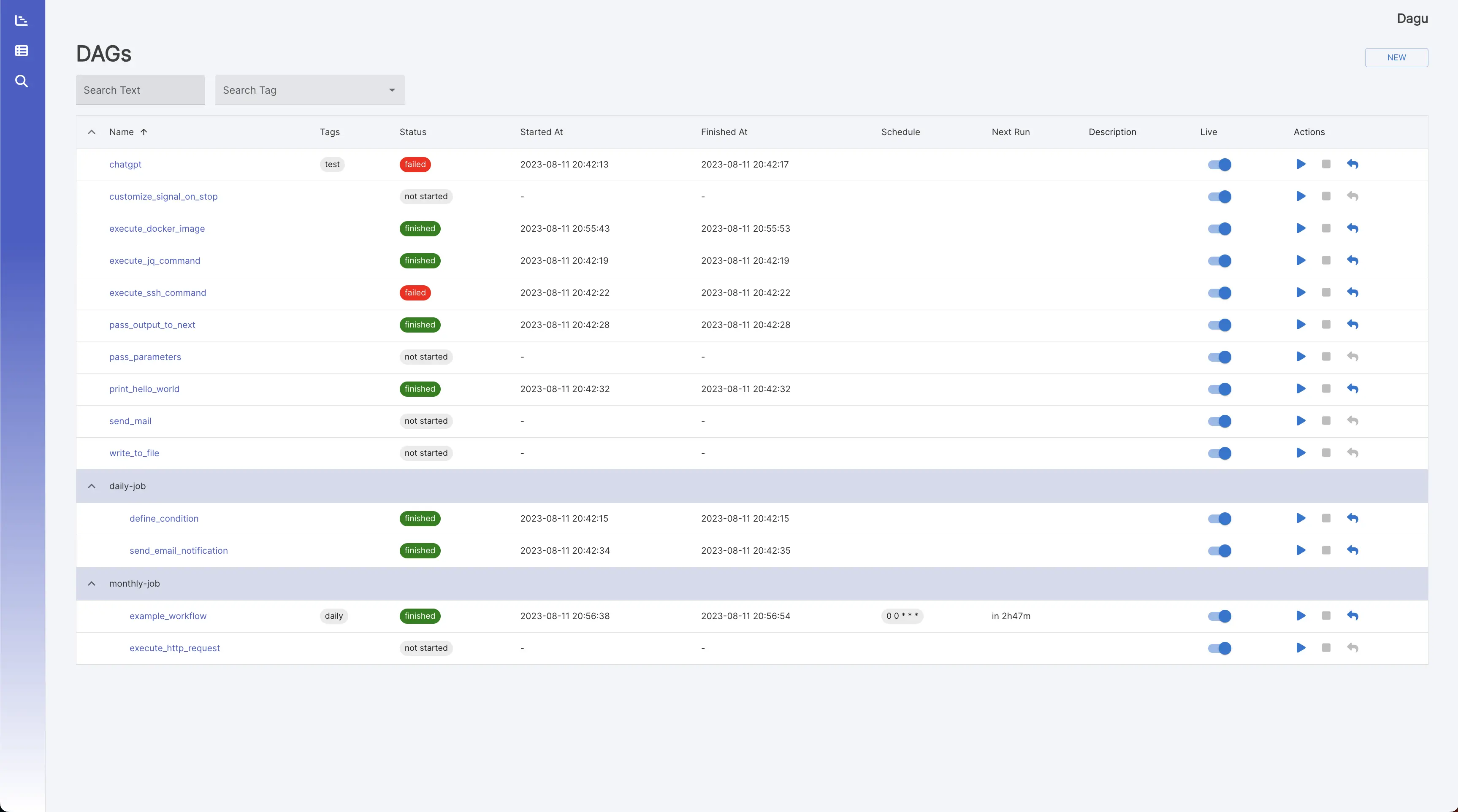
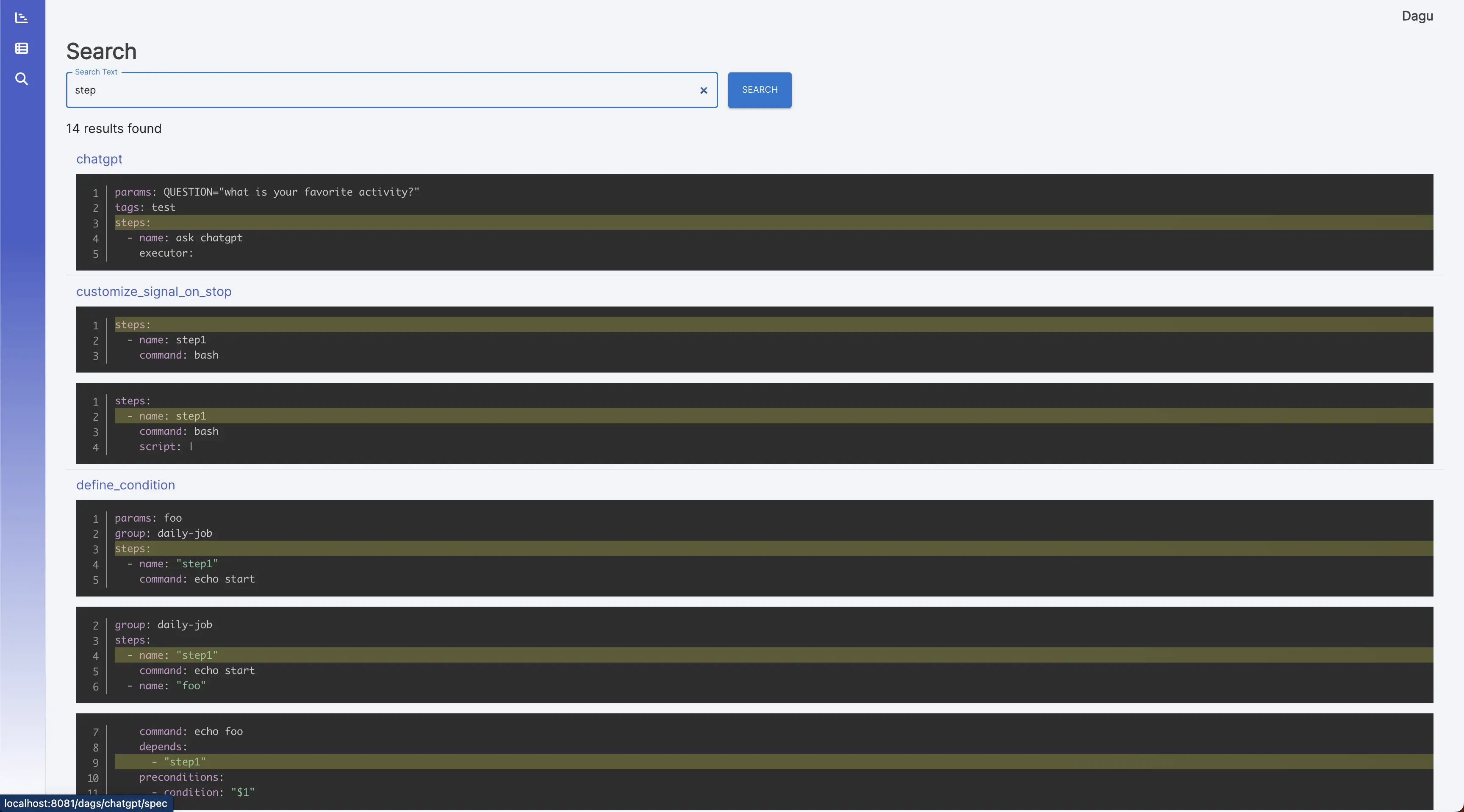
It greps given text across all DAG definitions.
It shows past execution results and logs.
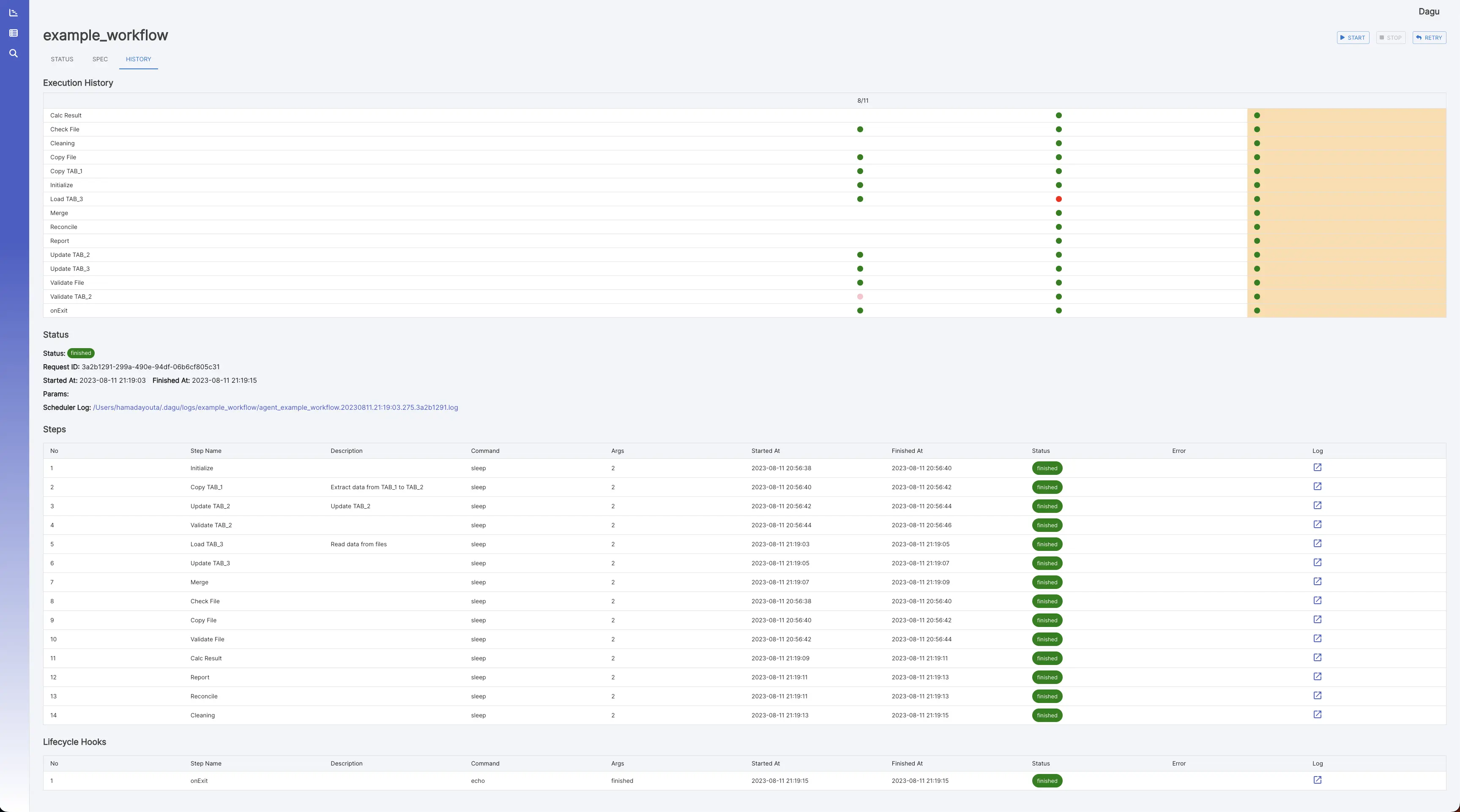
It shows the detail log and standard output of each execution and step.

You can install Dagu quickly using Homebrew or by downloading the latest binary from the Releases page on GitHub.
curl -L https://raw.githubusercontent.com/daguflow/dagu/main/scripts/installer.sh | bashDownload the latest binary from the Releases page and place it in your $PATH (e.g. /usr/local/bin).
brew install daguflow/brew/daguUpgrade to the latest version:
brew upgrade daguflow/brew/dagudocker run \
--rm \
-p 8080:8080 \
-v $HOME/.config/dagu/dags:/home/dagu/.config/dagu/dags \
-v $HOME/.local/share/dagu:/home/dagu/.local/share/dagu \
ghcr.io/daguflow/dagu:latest dagu start-allSee Environment variables to configure those default directories.
Start the server and scheduler with the command dagu start-all and browse to http://127.0.0.1:8080 to explore the Web UI.
Navigate to the DAG List page by clicking the menu in the left panel of the Web UI. Then create a DAG by clicking the NEW button at the top of the page. Enter example in the dialog.
Note: DAG (YAML) files will be placed in ~/.config/dagu/dags by default. See Configuration Options for more details.
Go to the SPEC Tab and hit the Edit button. Copy & Paste the following example and click the Save button.
Example:
schedule: "* * * * *" # Run the DAG every minute
steps:
- name: s1
command: echo Hello Dagu
- name: s2
command: echo done!
depends:
- s1You can execute the example by pressing the Start button. You can see "Hello Dagu" in the log page in the Web UI.
# Runs the DAG
dagu start [--params=<params>] <file>
# Displays the current status of the DAG
dagu status <file>
# Re-runs the specified DAG run
dagu retry --req=<request-id> <file>
# Stops the DAG execution
dagu stop <file>
# Restarts the current running DAG
dagu restart <file>
# Dry-runs the DAG
dagu dry [--params=<params>] <file>
# Launches both the web UI server and scheduler process
dagu start-all [--host=<host>] [--port=<port>] [--dags=<path to directory>]
# Launches the Dagu web UI server
dagu server [--host=<host>] [--port=<port>] [--dags=<path to directory>]
# Starts the scheduler process
dagu scheduler [--dags=<path to directory>]
# Shows the current binary version
dagu version- Installation Instructions
- ️Quick Start Guide
- Command Line Interface
- Web User Interface
- Writing DAG
- Minimal DAG Definition
- Running Arbitrary Code Snippets
- Environment Variables
- Parameters
- Command Substitution
- Conditional Logic
- Environment Variables with Standard Output
- Redirecting Stdout and Stderr
- Lifecycle Hooks
- Repeating Task
- Minimal DAG Definition
- Running Sub-DAG
- All Available Fields for a DAG
- All Available Fields for a Step
- Example DAGs
- Configurations
- Scheduler
- Docker Compose
- REST API Documentation
The easiest way to make sure the process is always running on your system is to create the script below and execute it every minute using cron (you don't need root account in this way):
#!/bin/bash
process="dagu start-all"
command="/usr/bin/dagu start-all"
if ps ax | grep -v grep | grep "$process" > /dev/null
then
exit
else
$command &
fi
exitThis example DAG showcases a data pipeline typically implemented in DevOps and Data Engineering scenarios. It demonstrates an end-to-end data processing cycle starting from data acquisition and cleansing to transformation, loading, analysis, reporting, and ultimately, cleanup.
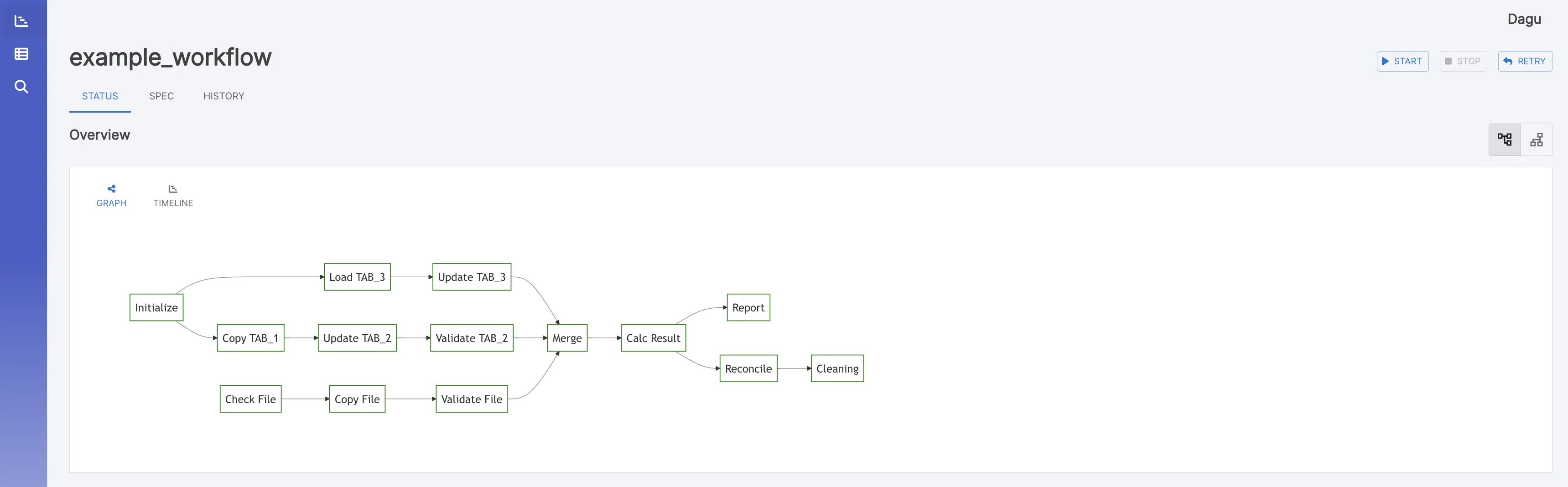
The YAML code below represents this DAG:
# Environment variables used throughout the pipeline
env:
- DATA_DIR: /data
- SCRIPT_DIR: /scripts
- LOG_DIR: /log
# ... other variables can be added here
# Handlers to manage errors and cleanup after execution
handlerOn:
failure:
command: "echo error"
exit:
command: "echo clean up"
# The schedule for the DAG execution in cron format
# This schedule runs the DAG daily at 12:00 AM
schedule: "0 0 * * *"
steps:
# Step 1: Pull the latest data from a data source
- name: pull_data
command: "sh"
script: |
echo `date '+%Y-%m-%d'`
output: DATE
# Step 2: Cleanse and prepare the data
- name: cleanse_data
command: echo cleansing ${DATA_DIR}/${DATE}.csv
depends:
- pull_data
# Step 3: Transform the data
- name: transform_data
command: echo transforming ${DATA_DIR}/${DATE}_clean.csv
depends:
- cleanse_data
# Parallel Step 1: Load the data into a database
- name: load_data
command: echo loading ${DATA_DIR}/${DATE}_transformed.csv
depends:
- transform_data
# Parallel Step 2: Generate a statistical report
- name: generate_report
command: echo generating report ${DATA_DIR}/${DATE}_transformed.csv
depends:
- transform_data
# Step 4: Run some analytics
- name: run_analytics
command: echo running analytics ${DATA_DIR}/${DATE}_transformed.csv
depends:
- load_data
# Step 5: Send an email report
- name: send_report
command: echo sending email ${DATA_DIR}/${DATE}_analytics.csv
depends:
- run_analytics
- generate_report
# Step 6: Cleanup temporary files
- name: cleanup
command: echo removing ${DATE}*.csv
depends:
- send_reportLegacy systems often have complex and implicit dependencies between jobs. When there are hundreds of cron jobs on a server, it can be difficult to keep track of these dependencies and to determine which job to rerun if one fails. It can also be a hassle to SSH into a server to view logs and manually rerun shell scripts one by one. Dagu aims to solve these problems by allowing you to explicitly visualize and manage pipeline dependencies as a DAG, and by providing a web UI for checking dependencies, execution status, and logs and for rerunning or stopping jobs with a simple mouse click.
Dagu addresses these pain points by providing a user-friendly solution for explicitly defining and visualizing workflows. With its intuitive web UI, Dagu simplifies the management of workflows, enabling users to easily check dependencies, monitor execution status, view logs, and control job execution with just a few clicks.
There are many existing tools such as Airflow, but many of these require you to write code in a programming language like Python to define your DAG. For systems that have been in operation for a long time, there may already be complex jobs with hundreds of thousands of lines of code written in languages like Perl or Shell Script. Adding another layer of complexity on top of these codes can reduce maintainability. Dagu was designed to be easy to use, self-contained, and require no coding, making it ideal for small projects.
Dagu is a single command line tool that uses the local file system to store data, so no database management system or cloud service is required. DAGs are defined in a declarative YAML format, and existing programs can be used without modification.
Feel free to contribute in any way you want! Share ideas, questions, submit issues, and create pull requests. Check out our Contribution Guide for help getting started.
We welcome any and all contributions!
This project is licensed under the GNU GPLv3.
Join our Discord community to ask questions, request features, and share your ideas.