Home
GOlorize is a Cytoscape App for advanced network visualization, which uses Gene Ontology (GO) categories as a source of class information to direct the layout process and to emphasize the biological function of the nodes. The implementation of GOlorize is based on the BiNGO App, an efficient tool to determine the GO categories that are overrepresented in a selected part of a given network. The both plugins are used within Cytoscape, which is an open source bioinformatics software platform for visualizing and integrating molecular interaction networks. The main advantage of GOlorize compared to other graph layout tools is the possibility to incorporate the GO class information already in the node placement phase using a modified version of the force directed layout algorithm. An extra attraction force is mediated through additional class nodes which represent the GO categories of interest. This version of GOlorize enables also the usage of other node attribute information than GO categories when defining the node classes of interest. GOlorize takes full advantage of Cytoscape's sophisticated filtering, analysis and visualization properties, allowing the user to produce customized highquality network images.
NB: For use of GOlorize with recent (June 2016 and later) annotation files, see this post on Cytoscape Helpdesk. We will try to fix the issue as soon as possible.
Start Cytoscape, version 3.2+, and use the File menu from the Cytoscape main window to import the example network galFiltered.xgmml from the sampleData folder. Select GOlorize from the Cytoscape Apps menu to start the interactive layout process. There are two modes how to define the node classes being used in the network visualization. The default mode corresponds to finding overrepresented GO categories in the selected network using BiNGO, whereas the alternative mode allows the user to define the node classes based on other attributes, such as expression data, or attributes imported from external files. The default mode is demonstrated in detail in Steps 2-5.
Select a cluster of nodes in the network view, indicated in yellow nodes, which will be used as an input in the determination of GO categories that are statistically overrepresented in the network (see an example screenshot below). Click on the Start BiNGO button in the GOlorize window.
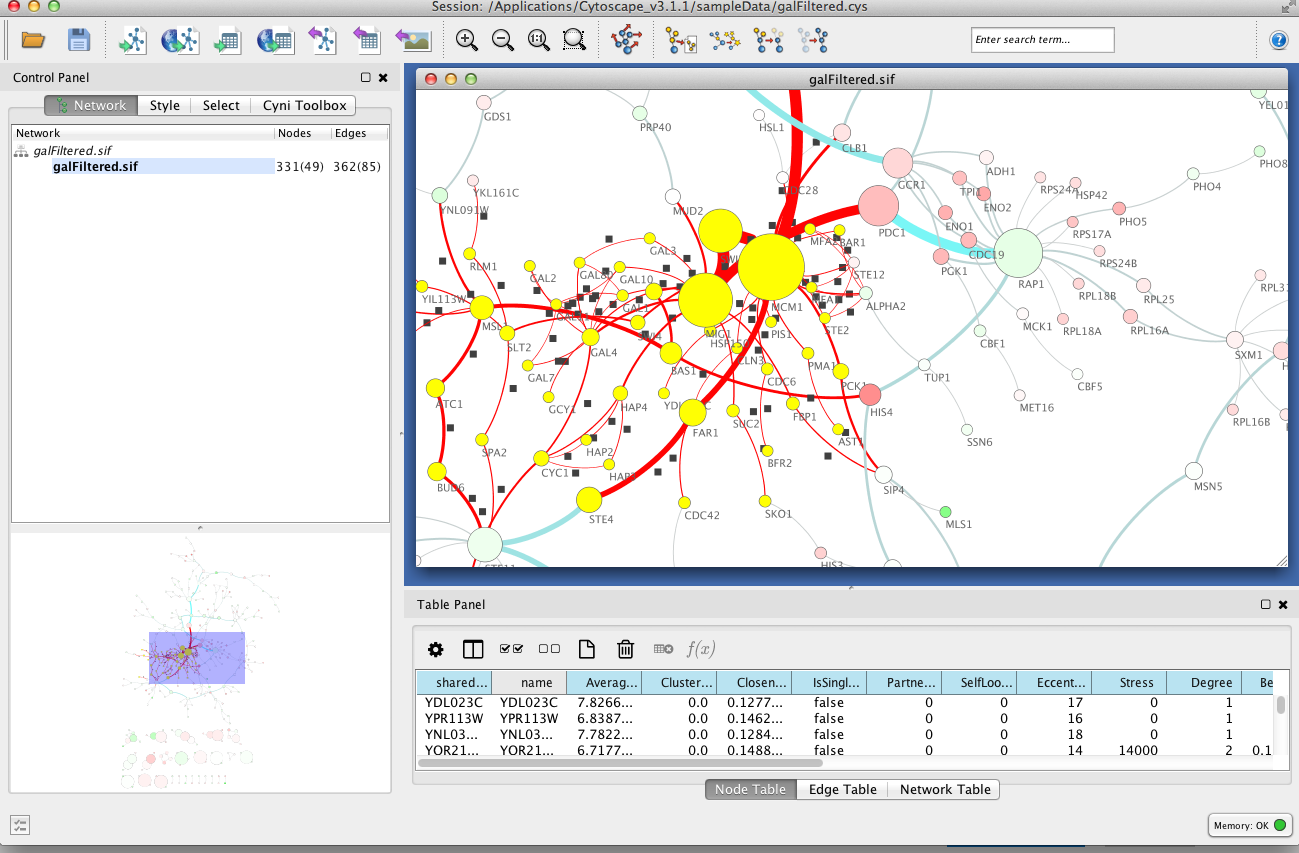
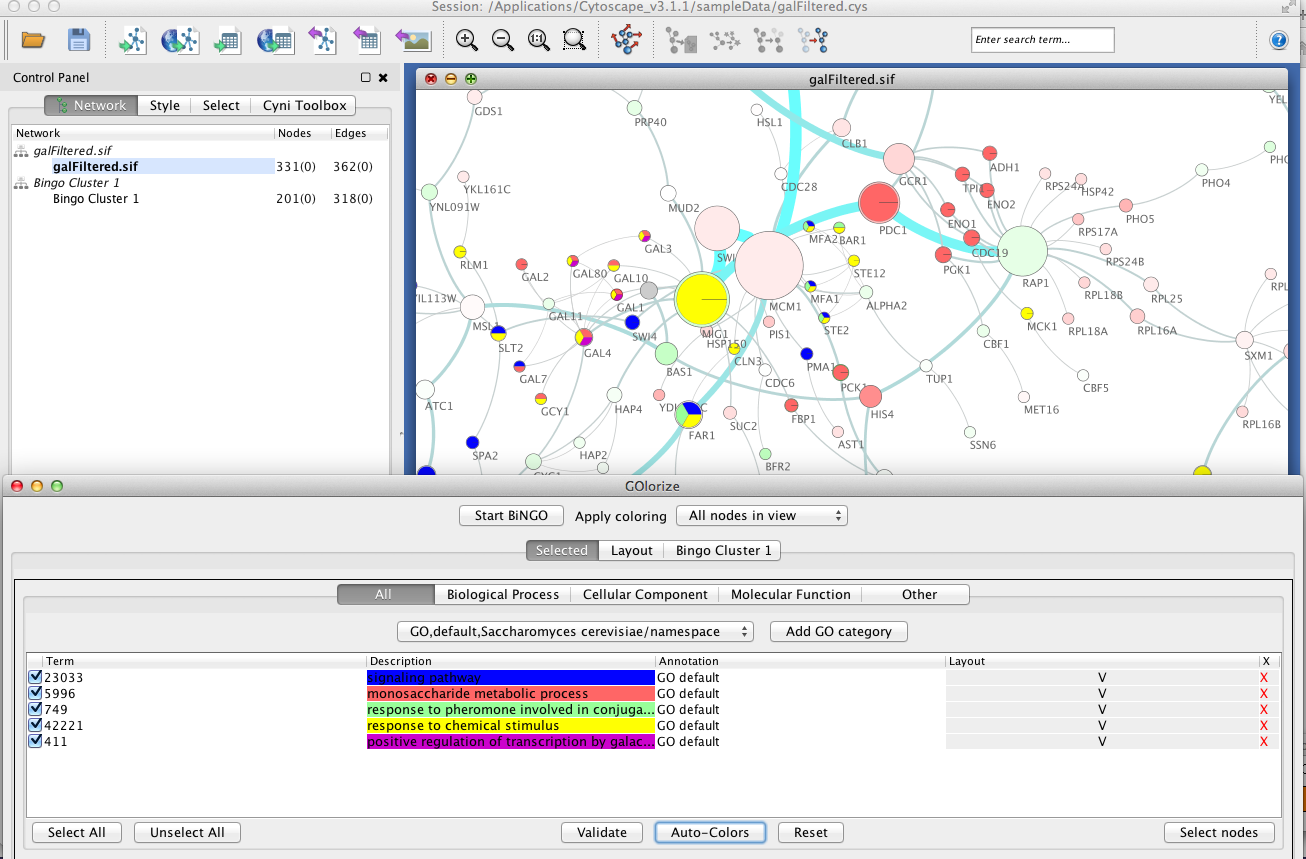
The BiNGO Settings panel pops up. In this panel, the user can specify several parameters for the GO overrepresentation analysis, such as the type of a statistical test and multiple testing correction used, as well as the significance level, e.g. p<0.05, which controls the number of enriched categories that will be outputted. For more information about the BiNGO settings and its operation. The particular selections for our example case are shown below. Press Start BiNGO button to proceed the example.
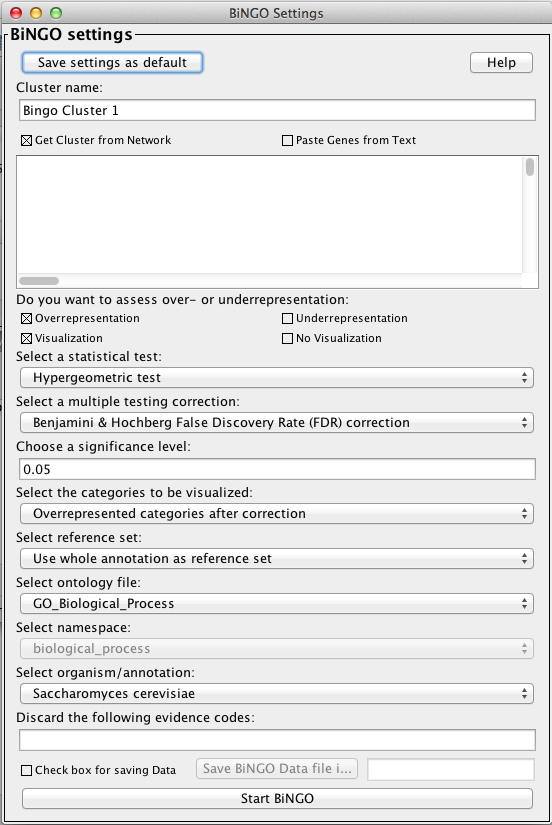
Having parsed the annotations and calculated the tests and their corrections, the BiNGO results appear in the GOlorize tab named after the BiNGO Settings Cluster name (Bingo Cluster 1 in the example below). This table lists the GO categories overrepresented in the selected subnetwork. The columns include the GO ID term of the category and its description, along with the original and corrected statistical significances (pval and corr pvalue), the number of nodes in the selected subnetwork and in the complete annotation that belong to the particular category (cluster freq and total freq), and the node IDs annotated to the category (either directly or to its parent categories).
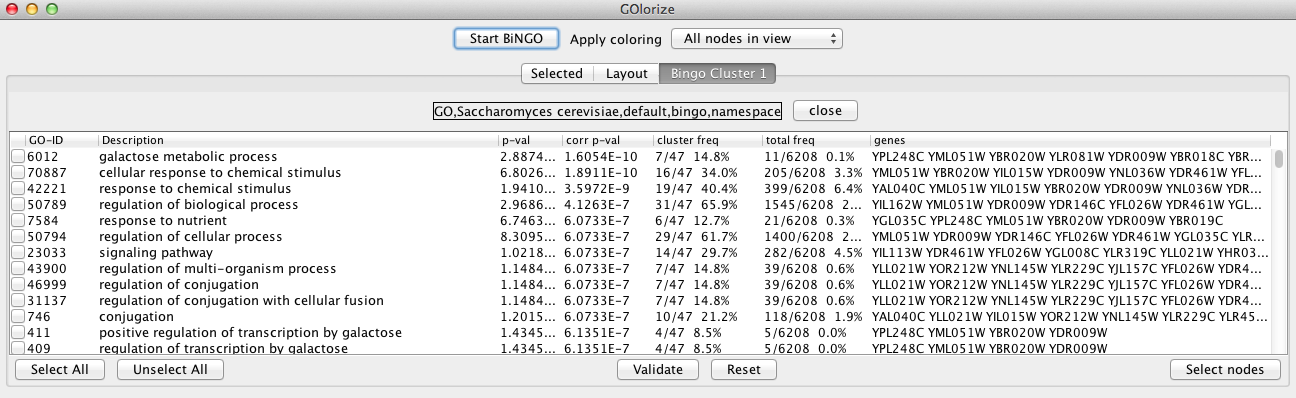
The user can choose the categories that will be applied in the layout by checking the corresponding rows. It is also possible to select categories from multiple overrepresentation analyses, by restarting the BiNGO again from the GOlorize panel, perhaps with different ontologies or parameter settings. Each BiNGO run is identified by its name in the tab list. The ontology being used is displayed above the categories (GO Biological Process of Saccharomyces cerevisiae ontology in the example case). After checking the categories of interest, press the Validate button and click the Selected tab.
In the Selected tab, all the GO categories selected from the BiNGO result(s) are shown. In this panel, the user can also manually add arbitrary GO categories by pressing the Add GO category button and typing the corresponding ID terms. In our example case, we have selected rather arbitrarily seven GO categories (shown below), which will be used in the network visualization process. Although class overlapping is allowed, we recommend not use more than 6 terms per node. It may be beneficial to select the categories of interest from the the higherlevel terms, rather than using very broad categories.
Clicking on he GO Term ID number (the first column below) in the Selected tab opens an AmiGO web page for the particular GO category. The page contains a detailed view of information on the GO annotation and it also allows the user to browse, query and visualize the crosslinks between the selected category and other available data from GO. The icons below the Layout column (V) indicate whether or not the corresponding categories will be used in the layout process, and the last column (X) can be used to exclude the categories from the subsequent node coloring and placement steps.
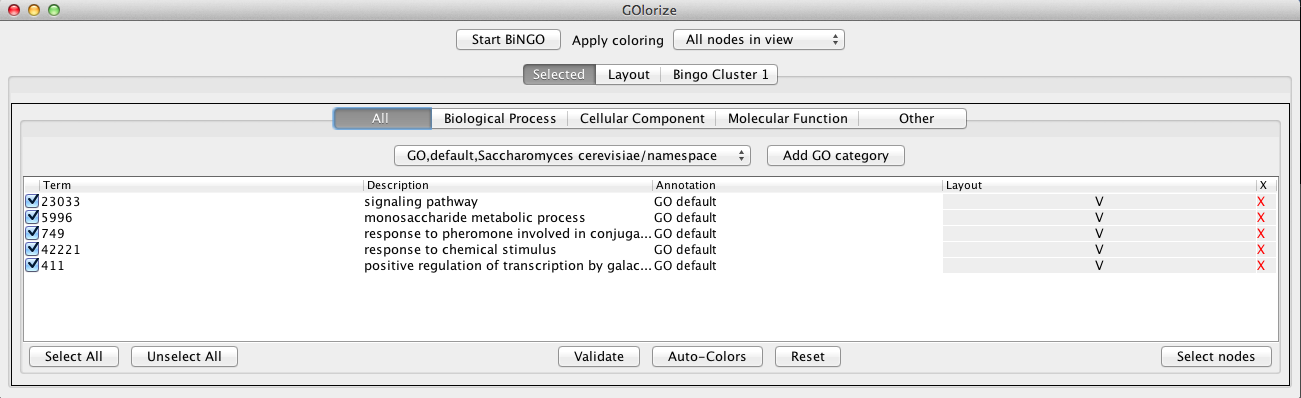
If desired, the visualization can be focused only on the neighborhood of the selected categories by node selection mechanisms. The Select nodes button applies to the categories with the leftmost checkboxes selected. In the example, we have selected all the nodes from the galFiltered network that belong to the five categories, as well as their first neighbors, and added them into a new network (a subnetwork with 184 nodes and 181 edges).
Pressing the AutoColors button generates automatically a colorcoding for the selected node classes. Alternatively, the user can manually choose the color of choice for each GO category. Due to hierarchical organization of the categories, each node can belong to none, unique or several classes. The unclassified nodes have the default node color of Cytoscape visualization, adjustable in Set Visual Style menu item. If a node belongs to several classes, a convenient pie coloring is applied. The user can also specify whether coloring is applied to all nodes in the network view or to selected nodes only.
The above layout shows that while the color coding can efficiently facilitate the visual interpretation of the class information, it is in many cases not enough for discovering whether or not the network contains a GO class structure superimposed on the underlying connection structure.
Our modified forcedirected layout algorithm finds the placement of the nodes based on both their connection structure (the original edges) and class structure (the selected GO categories). Globally, the operation of the classdirected layout algorithm is organized through the following three phases:
- Initial node placement using forcedirected optimization, where in addition to the standard attractive forces between each connected node, an extra attractive force is applied to the nodes belonging to the same class. The extra attraction is directed by adding virtual edges between class members and a virtual class node representing the particular class. This phase finds good initial positions for the class nodes.
- Subsequent separation of the classes by moving the class nodes in the same proportion away from the center of gravity of all nodes. This phase aims at providing maximal distinction between the different classes, while still preserving the relative placement of the nodes obtained in the initial layout phase.
- Final layout phase uses the same forcedirected optimization process as in the step 1, but with class nodes fixed to the positions determined in the step 2. The aim of the step is to finetune the placement of the actual nodes. Neither the virtual edges nor the class nodes are shown in the final visualization.
In the Layout tab, the user can specify the parameters of the above layout algorithm. The two key parameters are the strength of the attraction within a class in the layout phase 3 (termed IntraGroup Attraction 2) and the extent of which the class nodes are moved in the separation step 2 (InterGroup Distance). The example layout shown below corresponds to the default values of these two parameters (3 and 10), after pressing the Layout button. Again, the results can be different between two Cytoscape sessions, and even within the same session, due to random starting positions and movements.
Nodes that belong to the same class (indicated by the same color) are grouped together, and the nodes with multiple GO class memberships (pie coloring) lie typically in between their main classes. Unclassified nodes (white color) are placed according to their connection structure only (the edges). The Layout tab also allows user to control whether the placement of a class node in the in the final layout phase 3 is free or fixed to the location determined in the separation step 2. This is specified using the checkboxes under the column Group Separation, and it can help to decide placements for small or heavily overlapping node classes.
A nice feature of the layout algorithm is that it is capable of grouping the class members close to each other even if the original network was disconnected, especially if the IntraGroup Attraction is substantially larger than one. This is because the parameter is directly proportional to the standard attraction between connected nodes. Increasing the value of IntraGroup Attraction, and decreasing the value of InterGroup Distance respectively, results in more compact node classes (an example below). Such a layout emphasizes the connections between the classes (or metanodes), while the withinclass connections are not so clearly visible anymore.
In the Advanced Settings, the user can adjust also several other parameters, including the number of iterations performed in the two layout phases, the strength of the attraction within a class in the initial layout phase 1, and the strength of the standard attraction between two connected nodes (Density of nodes). Two alternative modes to the initial placement of the nodes is implemented – In the first one, all the nodes start from random positions, whereas in the second one, the standard and class nodes are initially placed on two circles within each other (this provides reproducible solutions within a session).