[Docs] Add Chinese dataflow markdown #2652
Conversation
|
|
||
|  | ||
|
|
||
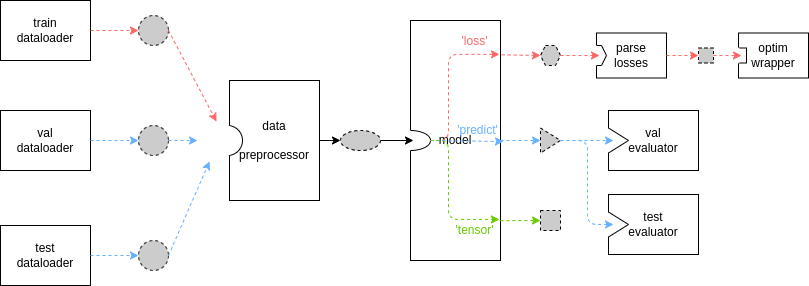
| 虚线边框、灰色填充形状代表不同的数据格式,而实心框表示模块/方法。由于 MMEngine 的极大灵活性和可扩展性,一些重要的基类可以被继承,并且它们的方法可以被覆写。 上图所示数据流仅适用于当用户没有自定义 `Runner`中的`TrainLoop`、`ValLoop` 和 `TestLoop`,并且没有在其自定义模型中覆写`train_step`、`val_step`和`test_step`方法时。MMSegmentation 中loop的默认设置如下:使用`IterBasedTrainLoop` 训练模型,共计20000次迭代,并且在每2000次迭代后进行一次验证。 |
There was a problem hiding this comment.
由于 MMEngine 的极大灵活性和可扩展性 --> 由于 MMEngine 极大的灵活性和可扩展性
| test_cfg = dict(type='TestLoop') | ||
| ``` | ||
|
|
||
| 在上图中,红色线表示[train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step)***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#train_step))***,在每次训练迭代中,数据加载器(dataloader)从存储中加载图像并传输到数据预处理器(data preprocessor),数据预处理器会将图像放到特定的设备上,并将数据堆叠到批处理中,之后模型接受批处理数据作为输入,最后将模型的输出发送给优化器(optimizer)。蓝色线表示[val_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step)和[test_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step)***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#test_step))***。这两个过程的数据流除了模型输出与`train_step`不同外,其余均和`train_step`类似。由于在评估时模型参数会被冻结,因此模型的输出将被传递给[Evaluator](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric)***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/evaluation.md#ioumetric))*** |
There was a problem hiding this comment.
use DBC parentheses between Chinese and English e.g.
数据加载器(dataloader)从存储中 --> 数据加载器(dataloader)从存储中
similarly hereinafter
There was a problem hiding this comment.
Sorry, I accidentally closed PR😥
| test_cfg = dict(type='TestLoop') | ||
| ``` | ||
|
|
||
| 在上图中,红色线表示 [train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step) ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#train_step))*** ,在每次训练迭代中,数据加载器 (dataloader) 从存储中加载图像并传输到数据预处理器 (data preprocessor),数据预处理器会将图像放到特定的设备上,并将数据堆叠到批处理中,之后模型接受批处理数据作为输入,最后将模型的输出发送给优化器 (optimizer)。蓝色线表示 [val_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step) 和 [test_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step) ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#test_step))*** 。这两个过程的数据流除了模型输出与 `train_step` 不同外,其余均和 `train_step` 类似。由于在评估时模型参数会被冻结,因此模型的输出将被传递给 [Evaluator](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric) ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/evaluation.md#ioumetric))*** |
There was a problem hiding this comment.
“数据加载器 (dataloader) 从存储中” 这个是需要用全角括号,不是半角加空格
|
|
||
| ### 数据加载器到数据预处理器 | ||
|
|
||
| 数据加载器(DataLoader)是 MMEngine 中训练和测试管道中的一个重要组件。 |
There was a problem hiding this comment.
数据加载器(DataLoader)是 MMEngine 中训练和测试管道中的一个重要组件。 --> 数据加载器(DataLoader)是 MMEngine 的训练和测试流程中的一个重要组件。
| ### 数据加载器到数据预处理器 | ||
|
|
||
| 数据加载器(DataLoader)是 MMEngine 中训练和测试管道中的一个重要组件。 | ||
| 从概念上讲,它源于 [PyTorch](https://pytorch.org/)。DataLoader 从文件系统加载数据,原始数据通过数据准备管道传递,然后将其发送到数据预处理器。 |
There was a problem hiding this comment.
从概念上讲,它源于 PyTorch 并保持一致。DataLoader 从文件系统加载数据,原始数据通过数据准备流程后被发送给数据预处理器。
|
|
||
| MMSegmentation 在 [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/datasets/transforms/formatting.py#L12) 中定义了默认数据格式, 它是 `train_pipeline` 和 `test_pipeline` 的最后一个组件。有关数据转换 `pipeline` 的更多信息,请参阅[数据转换文档](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/transforms.html)。 ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/transforms.html))*** | ||
|
|
||
| 在没有任何修改的情况下, PackSegInputs 的返回值通常是一个包含 `inputs` 和 `data_samples` 的 `dict`。以下伪代码展示了 mmseg 中数据加载器输出的数据类型,它是从数据集中获取的一批数据样本,数据加载器将它们打包成字典列表。`inputs` 是输入进模型的张量列表,`data_samples` 包含了输入图像的 meta information 和相应的 ground truth。 |
There was a problem hiding this comment.
数据加载器将它们打包成字典列表 --> 数据加载器将它们打包成一个字典列表
| pass | ||
| ``` | ||
|
|
||
| **注意:** 模型的前向传播有 3 种模式,由输入参数 mode 控制,更多信息请参阅[模型教程](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html)。 ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/models.html))*** |
There was a problem hiding this comment.
| ### 模型输出 | ||
|
|
||
| 如[模型教程](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#forward) ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#forward))*** 所提到的 3 种前向传播具有 3 种输出。 | ||
| `train_step` 和 `test_step`(or `val_step`) 分别对应于 `'loss'` and `'predict'`。 |
| 如[模型教程](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#forward) ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#forward))*** 所提到的 3 种前向传播具有 3 种输出。 | ||
| `train_step` 和 `test_step`(or `val_step`) 分别对应于 `'loss'` and `'predict'`。 | ||
|
|
||
| 在 `test_step` 或 `val_step` 中,推理结果被传递到 `Evaluator` 中。您可以参阅[评估文档](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/evaluation.html) ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/evaluation.html))*** 来获取更多关于 `Evaluator` 的信息。 |
There was a problem hiding this comment.
推理结果被传递到 Evaluator 中 --> 推理结果会被传递给 Evaluator
|
|
||
| - dict\[str, Tensor\]: 损失组件的字典 | ||
|
|
||
| **注意:** `train_step` 将损失传递进OptimWrapper以更新模型中的权重, 更多信息请参阅 [train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step)。 ***([中文链接待更新](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#train_step))*** |
| 参数: | ||
|
|
||
| - seg_logits (Tensor): 解码头前向函数的输出 | ||
| - batch_data_samples (List\[:obj:`SegDataSample`\]): seg 数据样本,通常包括如 `metainfo` 和 `gt_sem_seg`等信息 |
| - seg_logits (Tensor): 解码头前向函数的输出 | ||
| - batch_data_samples (List\[:obj:`SegDataSample`\]): seg 数据样本,通常包括如 `metainfo` 和 `gt_sem_seg`等信息 | ||
|
|
||
| 返回: |
|
|
||
| 返回: | ||
|
|
||
| - dict\[str, Tensor\]: 损失组件的字典 |
|
|
||
| ### 数据预处理器到模型 | ||
|
|
||
| 虽然在[上面的图](https://github.com/open-mmlab/mmsegmentation/edit/dev-1.x/docs/zh_cn/advanced_guides/data_flow.md#%E6%95%B0%E6%8D%AE%E6%B5%81%E7%A8%8B%E6%A6%82%E8%BF%B0)中分开绘制了数据预处理器和模型,但数据预处理器是模型的一部分,因此可以在[模型教程](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html)中找到数据预处理器章节。 ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/models.html))*** |
There was a problem hiding this comment.
Of course. What should I do to give you access? |
Signed-off-by: csatsurnh <[email protected]>
Sorry, it's done |
## Modification Add Chinese dataflow markdown --------- Signed-off-by: csatsurnh <[email protected]> Co-authored-by: csatsurnh <[email protected]> Co-authored-by: Miao Zheng <[email protected]>
Modification
Add Chinese dataflow markdown