Questions on parallelization #71
Comments
First of all, you should note that in some applications, there are legitimate reasons for the CPU utilization to be low. For example, if the main computational cost is to run inference and inference runs on GPU, having a high number of CPUs simply isn't useful as there just isn't enough work for them. One way to figure out whether or not this is the case is to profile network inference and vanilla MCTS separately and compare the numbers. In your case, you seem to be using a very small network so I doubt inference would be the only bottleneck though. Also, if you are doing inference on CPU, note that the inference server is only going to use a single CPU because of this line, which you may want to try and comment out (restricting inference to one core is sometimes useful to avoid too much cache thrashing but it may backfire here). Low CPU utilization may also be due (at least in part) to some GC or multitasking overhead. Indeed, even if you are not using a GPU (whose interaction with the Julia GC raises known issues), the Julia GC sometimes has problems at dealing with multiple threads that allocate a lot (this being worked on right now as far as I understand). Unfortunately, the current tools are not great for detecting and quantifying this kind of overhead.
The benefits will certainly be greatly reduced but even a CPU can exploit some amount of parallelism so batching inference queries can be worth it, up to a point where the overhead of having many workers becomes too large (more allocations, more cache invalidation and context switching...)
You may be referring to this figure, which I created for an old version and haven't regenerated since.
The only interest of using multiple processes is if you want to leverage multiple GPUs (as CUDA.jl used to have very poor multi-gpu support) or distribute the computtion on a cluster of machines. Also, I believe that in recent versions Julia starts multiple threads by default unless you pass the
The network you are using is so small that the overhead of transferring data to the GPU is probably much higher than doing inference on CPU so I am not surprised here.
I removed it for the sake of simplicity as I was refactoring the code and realized that in most applications, batching inference requests across game simulations is enough and does not lead to the exploration bias induced by the use of a virtual loss. More general adviceMy more general advice for you is to start by running a lot of small profiling experiments: how much does it cost to simulate a step in my environment? How much does it cost to evaluate a batch using the CPU/GPU. What is the ideal batch size for my config? Once you've done this, you can get a back-of-the-envelope estimate for the ideal performances you should expect from the full training loop, assuming no GC/multitasking overhead. Then, you can compare this number to the actual performances you are currently getting and only then work on reducing the gap. |
|
Thank you for the detailed answer, this is much appreciated!
Alright, I will do some profiling to get a better feeling for that.
Yes, that's what I was looking for! Thanks, even though this is probably not relevant anymore then.
Conceptually, I understand this and agree. However, I'm wondering if it could still be useful is this case since multi-threading seems to not fully utilize resources and batching inferences seems less valuable when not using a GPU. I will do more experiments to see which configuration of threads and processes is fastest.
Thanks, I will do that! |
|
Hi, Interesting topic. I have been doing training purely on CPU machines. No changes to the AlphaZero code with the exception of use_gpu set to false in parameters file. My observations:
I found the following question asked by johannes-fischer particularly interesting:
Would it be possible to receive additional information on this topic please? Best regards! Edit: some typos |
|
It is interesting and surprising that using several processes is so much faster than using several threads. A possible advantage of processes over threads is that they each have their own GC and so each process can collect its garbage without stopping the world (this should be improved in the future). But could this explain an order of magnitude difference? I feel like I am missing something here and I would like to understand this better. Also, @idevcde: this sounds like you observed a significant slowdown during training. Is it possible that the system was simply using too much memory and ended up spending too much time fetching pages from the swap? Did you look at the ratio of time spent in GC in the generated report? More generally, I must admit that AlphaZero.jl could be more efficient in the way it handles memory (using async MCTS to diminish the number of MCTS trees to maintain without diminishing batch size, MCTS implementation without state sharing, storing samples on disk...). That being said, I've had several reports of increasing memory consumption during training to an extent that I find surprising. I do not see how AlphaZero.jl could be leaking memory (as there is very little shared state between iterations) and so I would like more data on this. May the GC be at fault once again?
Could it be BLAS spawning 8 threads to perform the linear algebra during inference? The number 8 also appears here: JuliaLang/LinearAlgebra.jl#671. |
|
Thank you.
I have to admit that I am surprised as well. I was expecting multithreading being faster.
I just checked the notes and unfortunately it seems that I do not have any notes on those stopped pure multithreading trainings. I think that the fist step ("Self play") was about 5-10 times slower vs Distributed training with the number 10 being closer to my judgement.
I do training using the following code: using Distributed Julia 1.6.1. and Julia 1.7 beta3, AlphaZero, MKL and LinearAlgebra as the only additional Julia packages installed. No changes to the code, with exception of gpu set to false. All successful trainings with libopenblas64_.so. (or at last for 1.7 beta3 as I was not checking it for 1.6.1 so no MKL, however, my guess is that it was the same).
I guess you are referring to multithread trainings. Because as for Distributed, I have to admit that I am pretty happy with the times on CPU only machine, especially for the first step (Self play) which took 3:48:29 at Iteration 11.
Unfortunately I did not. I will try to further investigate the topic of swap/GC and will also try to consult with some of my colleagues. Should I be able to provide additional information I will do it here.
According to the best of my knowledge there are no memory leaks. However, please be advised that I am not an ultra experienced developer.
Thank you. As for the BLAS, somehow, the previous link provided by you seemed not to work and it was not readable upfront. I will try to investigate this topic further when time permits. As for the BLAS, I have one additional question. I am also wondering if the use of MKL library might bring any benefit? Iteration 1-9 I trained on Julia 1.6.1. with libopenblas64_.so. Iteration 10 and 11 on Julia 1.7 beta 3 which I understand brings native support for libmkl_rt.so when using MKL package. In general on simple matrix multiplication I saw about 30% decrease of calculation time on one of the machines (I think it was Intel Xeon Gold 6128 CPU @ 3.40GHz) when using libmkl_rt.so vs libopenblas64_.so. However, when trying to launch AZ training with MKL I received the following error: OMP: Error JuliaLang/julia#34: System unable to allocate necessary resources for OMP thread: signal (6): Aborted I did the MKL test without using Distributed. AlphaZero, MKL as the only additional Julia packages installed. The code as follow: using MKL Do you have any opinion? And additional advice or comment on this topic/s? Best regards! Edit: removed "and LinearAlgebra". Was: "AlphaZero, MKL and LinearAlgebra as the only additional Julia packages installed." Is: "AlphaZero, MKL as the only additional Julia packages installed." |
@idevcde thanks for your insights, could you provide some more information on how many workers and threads you were using depending on the number of available CPUs to achieve best results?
@jonathan-laurent I had a look at some of the performance plots and it seems that GC in multi-processing is very small, but for only multi-threading is at around 40% of self-play (I didn't use both at the same time yet). In one multi-processing run GC jumped from 5% to 30% at iteration 28, though. I don't know, if swapping became necessary at this point. |
|
@johannes-fischer Thanks! This seems to indicate that a lot of the overhead we're seeing here comes from the GC not performing great with multiple heavily allocating threads. I am not sure the performance drop you are seeing has anything to do with swapping as I would expect swapping to slow down the program uniformly, but it is not the first weird GC behavior I have been observing. |
I am not sure if those are the absolute best possible results. Please be advised that I am new to this topic. However, I have tried more than a few different combinations. I am providing additional info.
I think that I achieved the best results in terms of computational time per iteration when using maximum number of available logical threads and maximum number of available logical distributed workers. I would say that using distributed workers run only on physical cores and at the same time using threads run only on physical cores is increasing computational time by more or less 10%. In addition I would say that using only distributed workers (no matter if they are run only on physical or on all logical cores) and not using threads at all is increasing computational time by additional 10%. As I wrote in my previous post, I would say that using only all available logical threads and not using distributed workers at all, makes the first part of the training (Self play) very slow, like 10 times slower. Moreover, as I wrote earlier, I saw full utilization of CPU (observed in "top -H" on Linux) only during the first part of the training (Self play). During later stages, I saw only about 8 workers mostly fully utilized and additional few (like additional 2 to 4) utilized at 5 to 25% from time to time). As I wrote earlier, I was able to run iteration 1 to 9 (average calculation time per 1 iteration was about 15.5h) on the first machine with 192GB RAM. Than I had to use a machine with more RAM as 192GB was insufficient. During iteration 11 on the second machine with 384GB RAM, the highest RAM utilization I spotted was about 320GB. Average calculation time for iteration 10 and 11 was about 22h (maybe slightly less, as in those cases I was not able to get very precise timings as calculations for next iteration started before I sent a break commands). At iteration 11 [julia -t 64 mytraining1.jl / using Distributed and addprocs(64)] I see the following results: Starting iteration 11 Starting self-play Starting learning Running benchmark: AlphaZero against MCTS (1000 rollouts) Running benchmark: Network Only against MCTS (1000 rollouts) @jonathan-laurent, @johannes-fischer Should you have any comments or any advise please let me know. Also do you think that trying to further investigate MKL.jl package that I mentioned earlier might be a good idea? I have also read about Octavian.jl. Does it make sense to investigate those kind of packages at all? |
@idevcde Thanks! So to make that explicit, on the machine with 64 logical cores you used julia with 64 worker processes and each of them used 64 threads? |
|
@idevcde Thanks for those details! I do not think it would be very useful to experiment with MKL.jl or Octavian.jl as I am pretty sure the performance problems do not come from whatever linear algebra library is used. The one thing you can try is comment out the following line in the Apart from this, the gap in performance probably results from a combination of GC / multitasking overhead. |
I think the inference might also play a major role in this. Currently, I'm running a training with only multi-threading (32 threads) and during running the MCTS only benchmark with RolloutOracle the CPU utilization is close to 3200%. But during self-play (and presumably also during AlphaZero benchmark) the CPU utilization drops to the previously reported levels. |
|
@johannes-fischer So the question here is: if inference is the bottleneck, how can we make sure that a high number of cores is dedicated to inference? Here, there are two things you can do:
|
Thanks! This I can not confirm. I wrote above that I did various experiments and I presented most of my findings above. As you can see results of iteration 11 presented above, for this particular run, I started Julia with 64 threads and than added 64 distributed worker processes. I do not understand in full the code inside AlphaZero.jl and I do not understand in detail what is going on under the hood.
Thanks! I will do the test ASAP, however, it may not be immediately.
Can I ask, out of the whole AlphaZero calculations, what percentage on average is linear algebra? Does it significantly differ among particular stages (self-play, learning, benchmark: AlphaZero against MCTS, benchmark: Network Only against MCTS)? If you look at the chart located at https://github.com/JuliaLinearAlgebra/Octavian.jl [https://raw.githubusercontent.com/JuliaLinearAlgebra/Octavian.jl/master/docs/src/assets/bench10980xe.svg] which side is more relevant to AlphaZero; left or right or maybe AlphaZero is out of this chart?
Edit: attached bench10980xe chart |

Thanks, afaik in this case only the main process has 64 threads whereas the workers are only single threaded (unless you use |
|
@johannes-fischer Thanks. This is a new information for me. I will check your suggestion when ... time permits. |
Did you have those ratios on your mind (report.json)? Please be advised that there were sometimes slightly different settings as I indicated above. All computations for iteration 1 to 9 on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz (2 sockets) with 192GB RAM, Julia 1.6.1., AlphaZero v0.5.0, [ILP64] libopenblas64_.so. All computations for iteration 10 and 11 on Intel(R) Xeon(R) Platinum 8153 CPU @ 2.00GHz with 384GB RAM (2 sockets), Julia Version 1.7.0-beta3.0 (2021-07-07), AlphaZero v0.5.1 or v0.5.0 (to be confirmed), [ILP64] libopenblas64_.so. <style> </style>
Loss iteration 1 vs 11 Performance iteration 1 vs 11 Summary iteration 1 vs 11 Enclosed: report.json files from /sessions/connect-four/iterations/ Edit:
Is it bad? |














|
I did some additional experiments on iteration 12. Hope my notes are correct.
I commented out this line. When using libopenblas64_.so on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz and
When using libmkl_rt.so on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz and
and a lot of additional info for a few if not for all (probably for all) other workers.
Below please find BLASBenchmarksCPU.jl results [rb = runbench(sizes = logspace(10, 10_000, 200)); plot(rb, displayplot = true);]. Julia started with -t 24 and -t 64 respectively to the following CPUs. Gold_6128_CPU_3.40GHz_192GB
Platinum_8153_CPU_2.00GHz_384GB
|








What exactly is your machine architecture / specification if I may ask? Is this all ... on one board? Would you consider providing additional information on training connect-four with default settings on CPU/GPUs? |
|
@jonathan-laurent Please be informed that I just spotted that AlphaZero was automatically updated to v0.5.2, so my parameters settings (use_gpu=false) and probably commenting out "LinearAlgebra.BLAS.set_num_threads(1)" might not be fully reflected (correctly) in some of my tests for Iteration 12 about which I wrote recently (#71 (comment)), in particular, this may be most relevant to the use of MKL in the process per core execution model. I will have to reevaluate and do some additional tests to confirm it for which I will continue using a perturbed parameter approach then I hope to switch to a perturbed-tendency and a stochastic back-scatter approaches also in order to cross-validate the probability distribution representing the uncertainty state as well as to get a better understanding of differences in the patterns of observed variables so the fastest growing characteristic patterns of differences might be correctly assessed with the use of appropriate uncertainty magnitudes and the multivariate extension of conjugate Bayesian updating of a Gaussian prior distribution. It is just a hobby project, however, please be informed that I am interested in better understanding your instructions level parallelism in order to take maximum advantage of all of the FLOPS on the machines. Should you have any additional comments or any advise please let me know. |
To be honest, I don't know. I also tried this configuration and to me it seemed as if it allocated a lot of RAM compared to multithreading on 1-2 workers. So currently I'm running experiments with 2 workers and 32 threads on each process.
Yes, it is a server with a AMD EPYC 7702P 64-Core Processor. I am not working on the connect-four problem for myself. I could probably still start a connect-four training with default settings, but the server is not only used by me. What configuration exactly are you interested in? |
|
In general, I have to admit that I am surprised that I was able to run iterations on a CPU only machine and to achieve the level described above at iteration 3. If one look at some videos and posts more or less, the picture drawn (or at least it was my understanding) is that it is almost intractable to use it on CPUs.
I understand, it is with Hyper Threading thus is the elevated level of RAM allocation. This configuration is one of the best I have found. I also found some additional notes on iteration 7, 8 and it seems that I run it with -p 12. The times seem to be good and despite I do not have precise notes, I would expect lower RAM utilization. I guess that HT on and off might be very dependent on a particular CPU.
What exactly are the commands and the code you are using? What are the results?
Currently, I am interested most to "achieve a very high CPU utilization". I was advised by a person with deep knowledge in this area that in case of MKL on Platinum 8153 and parallelized code (as I understand it) best would be to use OMP_NUM_THREADS=1 julia -p 32 -t 1 and to set BLAS.set_num_threads(1), and in case of single threaded Julia code calling expensive BLAS operations, best would be to set BLAS.set_num_threads(32). I did some tests with OMP_NUM_THREADS=1 julia -p 32 -t 1 and it seems to be that for iteration 12 I was able to achieve very similar timing for the first part of the training as during iteration 11 which I started with 64 threads and than added 64 distributed worker processes and used openblas with default AlphaZero settings. However, in case of iteration 12, the next part was done only on 1 thread whereas during iteration 11 I saw about 8 of them working. I broke this training and I do not have any details for the next phases. I also did a test with OMP_NUM_THREADS=1 julia -t 12, added 12 distributed worker processes and I set BLAS.set_num_threads(12) on 24 OCPU's machine. The times of the first part were comparable to achieved on Gold 6128, however, I would prefer not to provide details as I used a different 24 OCPU's machine than Gold 6128. What I think is interesting is that the learning phase (the second phase) in this case was done only on about two threads which were not fully utilized with %Cpu(s) at 4.3 us. As for now I do not have any details for the next phases. I will be busy, however, this is an interesting topic for me and I would be monitoring it. |
|
I gave this a little more thought and I suspect the most decisive way to move this debate forward is to have AlphaZero.jl produce some profiling information on how workers communicate with the inference server. I opened an issue with details here: #76 If anyone wants to have a go at it, this would constitute a major contribution to AlphaZero.jl. |
|
@jonathan-laurent Thank you for such an interesting package as AlphaZero.jl and for the suggestion as I understand of a new profiling package.
I understand that it is a lot of questions, however, I would appreciate even a very short answers. |
|
@idevcde Unfortunately, I do not currently have the time to engage more deeply in this conversation and answer all your questions. Here are a few thoughts though:
I am sorry I cannot be more helpful right now and I hope you can still manage to use AlphaZero.jl productively for your purposes. |
|
@jonathan-laurent I understand. Thank you. I will take it into a consideration. |
|
For completeness, of my "simple test" I am enclosing results of iteration 12 run on Intel(R) Xeon(R) Gold 6348 CPU @ 2.60GHz (2 sockets) with OMP_NUM_THREADS=1 julia -p 56 -t 1 mytraining1.jl and the settings provided at #71 (comment) (please see above point 4) and BLASBenchmarksCPU.jl results run with julia -t 112. |



If I may ask, how many GPUs? What are the clocks? What is your GPUs utilization? |
|
@johannes-fischer @idevcde I pushed a first version of the profiling functionality that I mentioned previously. It may require some mall modifications but I think you may find it useful in understanding the performances of AlphaZero.jl on your applications of choice. |
|
I might not be able to test this new functionality within the next few days, however, this is to my interest. Thank you. |
|
Awesome, thank you for the efforts! I will definitely try it out, but also not within the next two weeks. @idevcde I have not forgotten your question, but I didn't have the chance to try out the GPU utilization again yet. The machine has 5 GPUs but I'm not the only one using it. How can I determine the GPU clock speed? |
|
@johannes-fischer I should be able to take a look at the first version of the profiling functionality definitely sooner than two weeks, however, as for now, I prefer not to say exactly when. It seems that as suggested by @jonathan-laurent some additional insights might be useful. I usually use "nvidia-smi" with "-l 1" flags (nvidia-smi -l 1) which should give you a refresh interval of 1 second and "nvidia-smi -h" should bring a full list of customization flags. You may also want to try "watch -n 1 nvidia-smi" which refreshes the screen and "nvidia-smi > nvidia-output.txt" to save the output to a file. I believe there are many other ways. One additional thing that you may find interesting (I do not know, I assume you may) in relation to this thread, particularly when sharing a machine, is to run Julia with JULIA_EXCLUSIVE=1. This will assure Julia's thread policy is consistent and threads are affinitized. |
|
Enclosed please find reports for iteration 13 to 15 and detailed data for iteration 15 (training time ~11h) below. I understand number 15 is exhausting planned iterations in default version of AlphaZero.jl. For iteration 15 I collected profiling data. It was a different software than proposed by @jonathan-laurent, however, I belive the data is correct. Overall I noticed physical core utilization at a level of 11.1% (6.193 out of 56 cores), with more or less full physical core utilization for the first part of the training. I would like once again kindly point your attention to my questions included in #71 (comment): "What do you think about changing the number of MKL threads from 1 to the number of physical cores after the "Self play" stage? Do you think that it may be possible and could bring positive results? [...] If you think that this might not be possible, do you think that saving the "Self play" stage to "in memory file" and starting julia with different settings might bring any positive result?" I am currently trying the new profiling functionality proposed at #71 (comment). I still have to understand it better. Any additional instructions on its use, particularly with a focus on CPUs and non GUI environments would be appreciated. |
|
This is the output of the first try with the proposed profiling tool (#76). I adjusted the code as presented below to be run on non CUDA machine. Please be informed that in contrary to the previous post I did not use MKL. Should you have any comments please let me know. Any comments wrt use of CPUs and non GUI environments would be particularly welcomed. Please be informed that I have not noticed any JSON trace file. |
|
Hi, I see its pretty quiet here. FYI, I wanted to let you know that I am planning to do some additional tests on Julia 1.8 as BLAS there is potentially changed to 4096 threads with automatic detection of number of threads on startup. https://discourse.julialang.org/t/blas-performance-testing-for-julia-1-8/69520 This might not be immediately, and I am not sure if there is any significant performance gain to be expected, however, this is my plan for the relatively near future. I am aware that the tests above are not perfect, however, I tried to be as detailed and precise as possible at that moment. Would you have any suggestions with regard to the way how the software should be run on CPUs? I currently understand that this might be particularly important to confirm the setup before further experimenting with AlphaZero parameters. |
|
I am on As for now I understand that
What I was currently interested in was to balance the number of As |
Hi,
I'm currently trying to get AlphaZero running in full parallelization, but I'm having issues at all levels of parallelization. I'm new to parallelization, so I might also have misunderstood some parts. I'm running it on a machine with 128 CPUS, but I cannot achieve a very high CPU utilization, no matter if I try multi-threading or multi-processing.
Multi-threading (without GPU):

I have tried starting julia with different numbers of threads and different AlphaZero parameters, no matter if I start
julia -t 128orjulia -t 20,htoponly shows a CPU utilization of around 1200% for this process, so only around 12 threads are working. I was wondering if that is due to them waiting for the inference server, but I got similar results when using a very small dummy network. Also,SimParams.num_workerswas 128 and batch size 64, so shouldn't other workers continue simulations while some are waiting for the inference server? If the inference is the reason, would I be better off with a small batch size or a large batch size?When not using a GPU, are there benefits of batching inference requests at all? I.e. is it better to use multi-threading or multi-processing on one machine?
I also remember seeing a plot of AlphaZero performance over the number of workers somewhere in the AlphaZero.jl documentation or some post you made (i think), but I cannot find it anymore. Do you happen to know which plot I'm referring to?
Multi-processing (without GPU):
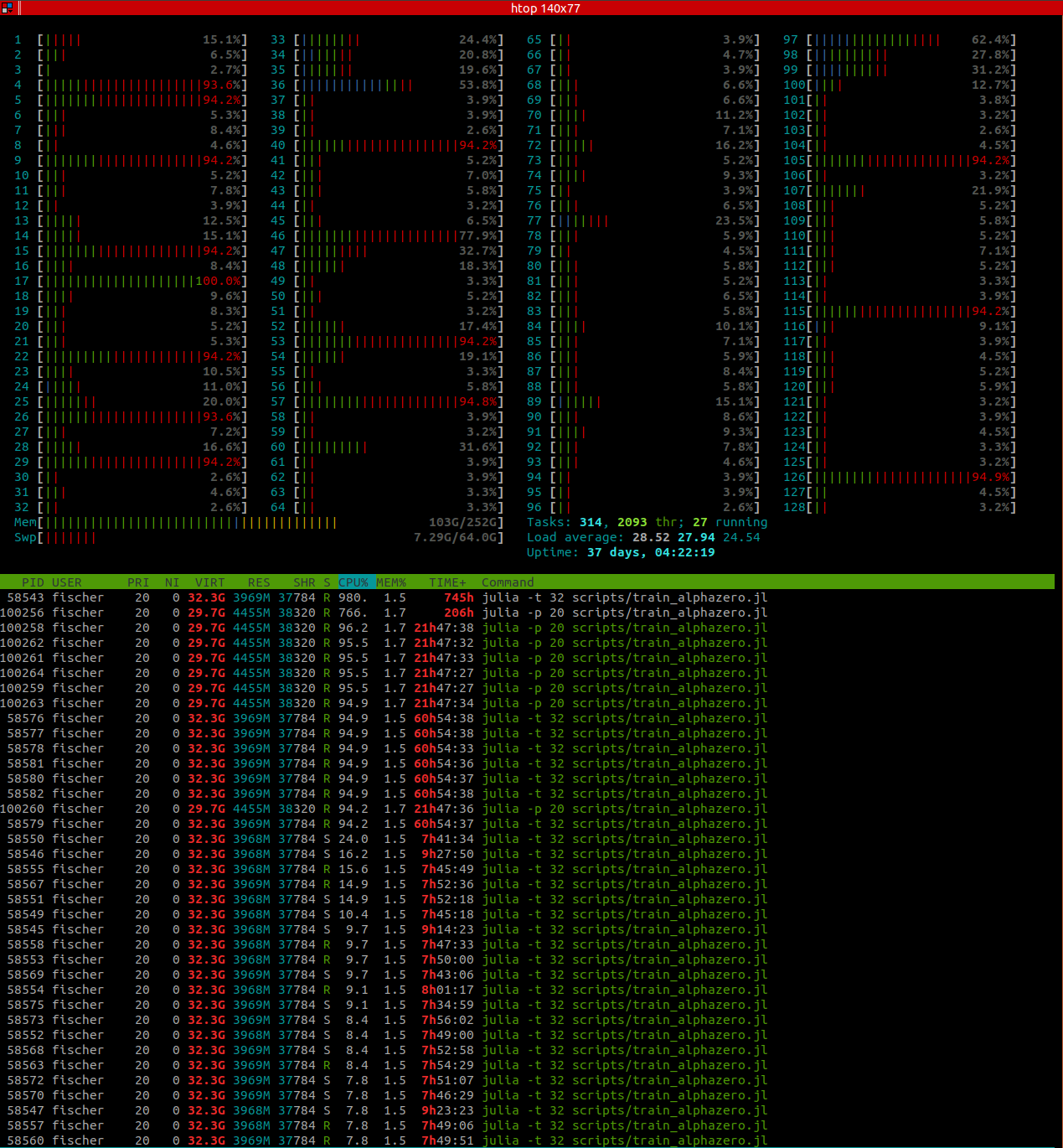
When using multiple processes (on the same machine, e.g.
julia -p 64),htopshows all workers having a high CPU load during self-play. However, if I understand correctly, this is a waste of resources, since each process has to start its own inference server. Or is this better when not using a GPU?What also confused me is that even even when calling single-threaded
julia -p 64,htopshows multiple threads belonging to the main process during benchmarking (where AlphaZero does not use multi-processing). This is not problematic, I'm just trying to understand what's happening. I don't see how Util.mapreduce spawns multiple threads sinceThreads.nthreads()should be 1. Furthermore, it is 8 threads that are working at full load (the ones fromjulia -p 20call, not 20, which would be the number of processes). So where does that number 8 come from?Using GPU:

When I try running AlphaZero.jl with GPU, for some reason it becomes incredibly slow, a lot slower than without GPU.
htopnow shows a CPU usage of around 500%:The machine has multiple GeForce RTX 2080 Ti with 10GB memory. Any ideas what could cause this?
Here are the parameters I used, in case this is relevant:
(
PWMctsParamsare for a progressive widening MCTS I've implemented for continuous states)As a general question, I was also wondering about why you removed the asynchronous MCTS version - is there simply no benefit because CPU power can also be used to parallelize over different MCTS tree instead of within the same tree?
Any help is appreciated!
The text was updated successfully, but these errors were encountered: