[WIP]Have restructured Position, TokenTup, LexBufState to be more memory &…… copy efficient #6010
Conversation
|
Wow, impressive improvement! Are the two screenshots interchangeable? I also notice large decreases of |
|
@abelbraaksma I recreated exact same steps in 4 iterations and so would have expected them to be same but have come down for some reason, it's critical someone else tests independently as should be similar |
|
@gerardtoconnor great! Nice job 😺 |
There was a problem hiding this comment.
Apart from my comment about EOF bit, everything here looks great. LexbufState shows up on the trace instead of TokenTup. Even though it shows on the trace, it looks to be significantly lower than before; which is an improvement and makes this change worth it.
Great work.
|
@abelbraaksma the |
|
@gerardtoconnor I will test your changes independently to verify perf results. Regardless, I still want to accept the change because it improves the code as well. |
|
@TIHan Thanks, left comment on the EOF flag, can put check on and allocate to new false if needed for true, re-use if already false. All checks passed using the same state … so we're missing test coverage or this is ok? If you can independently test that will be ideal, the allocations for |
…cidental additons in gitygnore
|
I haven't had time this evening to verify this. I will get back to it soon @gerardtoconnor . Code changes look good. CI is failing because of duplicate definition: |
|
Cheers GitHub "conflict resolution" , what happens when you edit code outside IDE. Have stripped out the duplicates it added there. Don't worry, there's no rush on the testing Merge … I have a few more PR's in the pipeline conserve your energy 😉 |
|
@gerardtoconnor Unfortunately, I don't have good news. Before your changes: After your changes: It regresses parsing performance by a significant amount even though we reduced allocations. I'm glad we caught this early. We need to have good benchmarking and evidence before we start pulling this stuff in. |
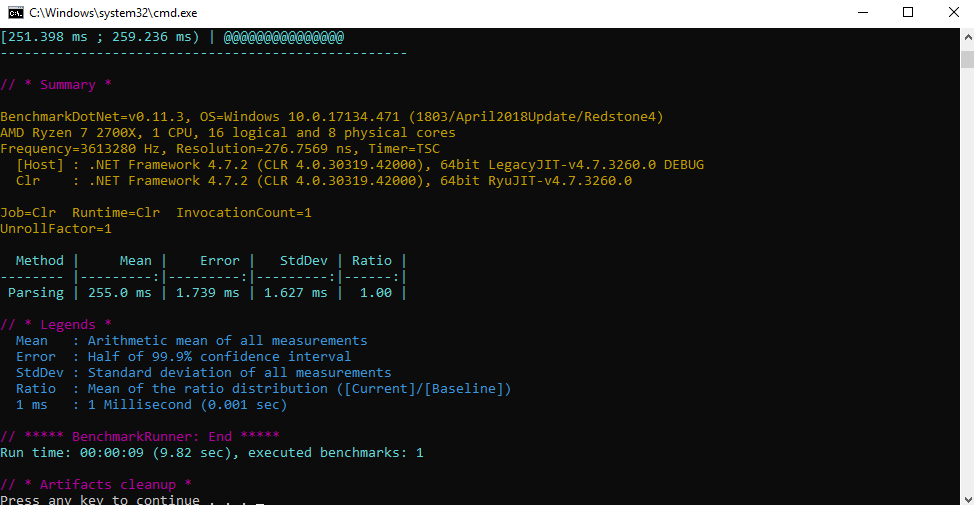

|
No that's fine, the Perfview traces were just trying to improve allocation times, why I wanted to get validated on entire use case. with the new benchmark in, will be easy to tweak till we get the right balance. |
|
Reducing allocations by changing stuff from structs to classes and vice versa, might be able to help; but from this evidence, the best way to approach this is to figure out how to do less work in |
|
Will I just close this and I can re-submit once we've figured a way to reduce without regressing perf on benchmark? |
|
I would prefer to keep this open due to discussion and visibility. If you want to re-do the PR, you can just force push override your branch here. |
|
I used the benchmark and it gave consistent results with you got, but the strange thing, for me at least, was that I could not find the TokenTup issue in memory running the benchmark while it turns up in VS service? |
|
Since the original issue is about slowing down VS as a result of memory congestion, it's possible that under high memory pressure, this PR would create a noticeable improvement, regardless of a slightly higher pressure on CPU in small projects. Whether the trade off is worth it I don't know. |
|
@gerardtoconnor My guess is because the benchmark is really just measuring one thing and not simulating real-world VS usage, you wouldn't see memory come up much. @abelbraaksma As a general rule we don't want to regress CPU time perf like this unless the memory usage is massively smaller (i.e., we solved The Issue ™️ that causes all these memory problems). Parsing is used by nearly every feature in the IDE, so slowing that down could make things feel worse for people who do not suffer large memory usage problems in the IDE today. |
|
@cartermp yeah I think we're all in consensus on that, aim is to reduce memory without materially impacting performance, this isn't enough to justify that slow down. I will keep looking for ways to compact the state & minimise allocs till we can get both memory down and, same if not better perf in benchmark, As @TIHan already said, will probably also require re-architecting the algo a bit. @abelbraaksma yeah its not the compromise I wanted to make and hence why was asking for the validation, it's reducing alloc times by 5% but slowing down plain lex case 20% so terrible trade-off. if it was 20% less memory and 5% slowdown it might be worth it so will just need to keep looking |
|
@gerardtoconnor I added [WIP], please let us know when you are ready to progress with this. Thanks, Kevin |
|
Would rather restructure the Lexer workflow then do these fringe tidy operations, especially as reduced allocations are not translating into better performance, will close this as regressing in real-world tests. |
PR for issue #6006
Looking into deeper and deeper, the allocation time was being spent doing all the coping of large structs like Position, a lot of the Position mutation related to just moving back and forward on the same line so I created a LinePosition Object that is used immutably, but meant Position Struct was now only an Absolute Postion, and a ref to a LinePosition. Now that there is less copying, and state objects are being passed by ref and not mutated, we are going from 8.7% >> 2% for these allocation & copying
(all tests done by going to line 6699 in TypeChecker.fs and erasing tokens (waiting), and replacing back (and waiting)
All tests passed except FSharpSuite ones … that never work for me!?
@TIHan @forki