{kind=link}
An LLM app leveraging RAG with LangChain and GPT-4 mini to analyze earnings call transcripts, assess company performance, evaluate management's track record by using natural language queries (NLP), FAISS (vector database), and Hugging Face re-ranking models.
Checkout out the deployed app here: http://ec2-40-177-46-181.ca-west-1.compute.amazonaws.com:8501
This readme provides a brief overview off the app, focusing on the app installation instructions. For more details, please checkout the blog here

FinRAGify is a user-friendly research tool designed to simplify the process of retrieving information from earnings calls of publicly traded companies. Users can select a company from a limited list (available for this proof-of-concept) and ask questions from a set of presets or create custom queries, such as "Were any new products launched?" or "What are the company’s future plans and outlook?" The app then searches (using embeddings) the last two years (8 quarters) of quarterly earnings calls by leveraging RAG (Retrieval-Augmented Generation) technology, a machine learning technique that combines retrieval-based and generative models (GPT, LLMs), to find and present contextually relevant answers.
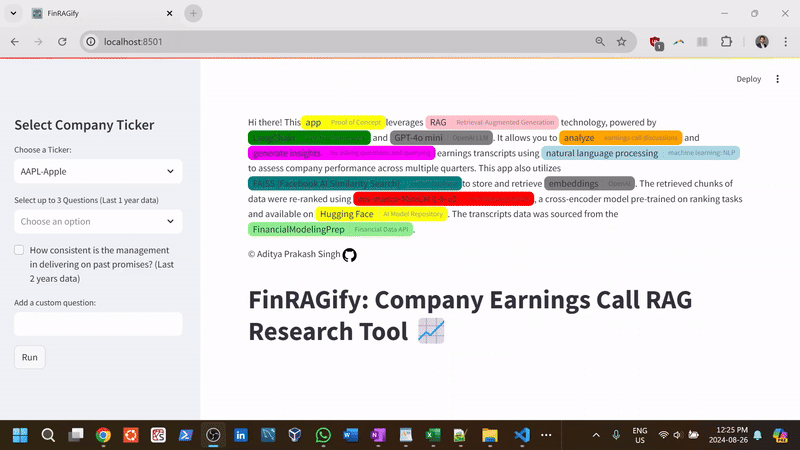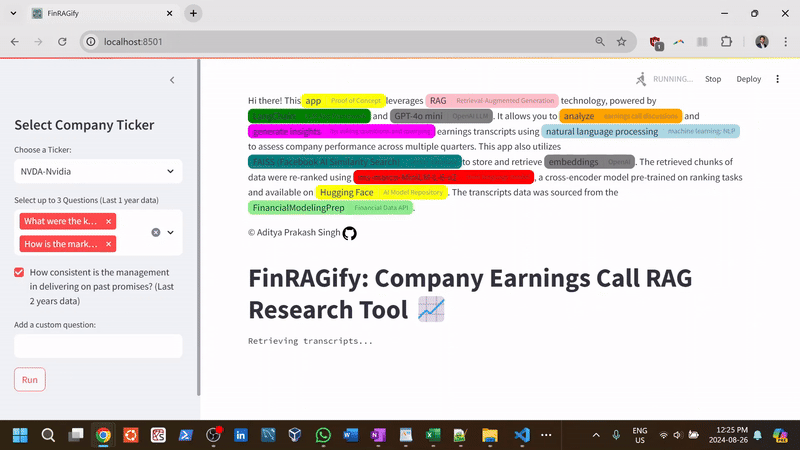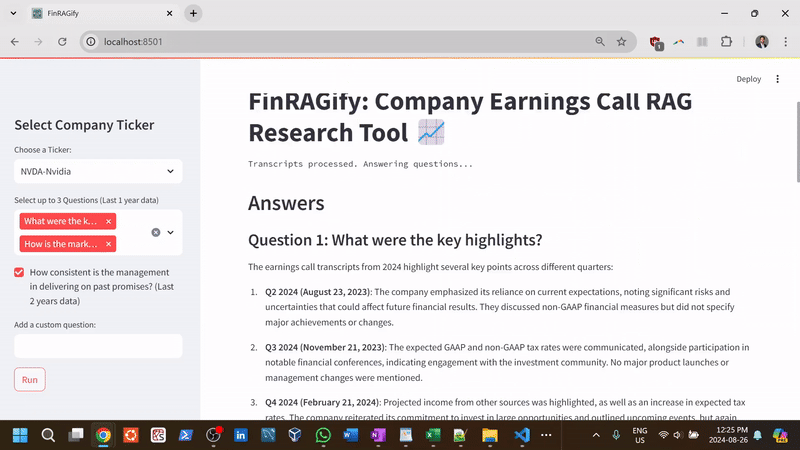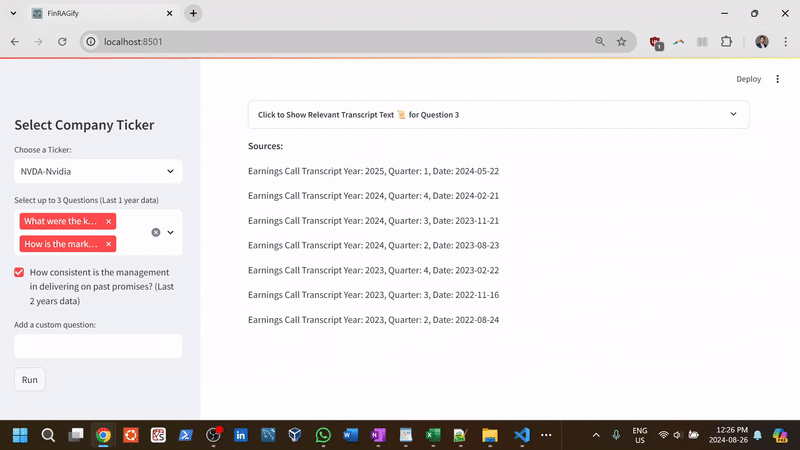
- Load and Process Earnings Call Transcripts: Fetch earnings call transcripts for selected stocks through the FinancialModelingPrep API, retrieving up to 8 quarters of data and sorting them by year and quarter.
- Embedding and Vector Store Creation: Construct embedding vectors using OpenAI's embeddings and store them in a FAISS (Facebook AI Similarity Search) vector store for fast and effective retrieval of relevant transcript chunks.
- Re-rank Documents for Relevance: Use a CrossEncoder model (ms-marco-MiniLM-L-6-v2) available on hugging face to re-rank retrieved transcript chunks and choose a smaller pool of the most relevant informatio for answering user queries.
- Preset and Custom Financial Questions: Offer a selection of preset financial questions focused on key business areas (e.g., future plans, product launches) with the flexibility to input custom queries.
- Management Consistency Analysis: Evaluate management's track record by comparing past promises with actual outcomes across multiple quarters, summarizing how often targets were met.
- main.py: The main Streamlit application script.
- backend_functions: The functions for the app are defined here.
- requirements.txt: A list of required Python packages for the project.
- .env: Configuration file for storing your OpenAI and FinancialModelingPrep API keys:
- dockerfile: The docker file to create the docker image if the user prefers to run the app by containerizing and deploying via Docker.
- lean_finragify: The repo for the light weight version of this app, which uses the Cohere Rerank API, instead of the open source CrossEncoder model (ms-marco-MiniLM-L-6-v2) for reranking the retrieved data chunks. This reduces the RAM requirements from 300- 600 MB to about 150-300 MB, which can be very helpful in deploying the app to smaller cloud compute instances like the AWS EC2 t3.micro. Please refer to the readme inside for installation instructions of that light version.
- Clone this repository to your local machine using:
git clone https://github.com/apsinghAnalytics/FinRAGify_App.git- Navigate to the project directory:
cd FinRAGify_APP- Create a local Python environment and activate it:
python3.10 -m venv venv
source venv/bin/activate # On Windows, use `venv\Scripts\activate`- Install the required packages, starting with the specific version of Torch (this must be installed before installing from requirements.txt):
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 --index-url https://download.pytorch.org/whl/cpu- Install the remaining dependencies from
requirements.txt:
pip install -r requirements.txt- Set up your API keys by creating a
.envfile in the project root and adding your keys:
OPENAI_API_KEY='your_openai_api_key_here'
FMP_API_KEY='your_fmp_api_key_here' 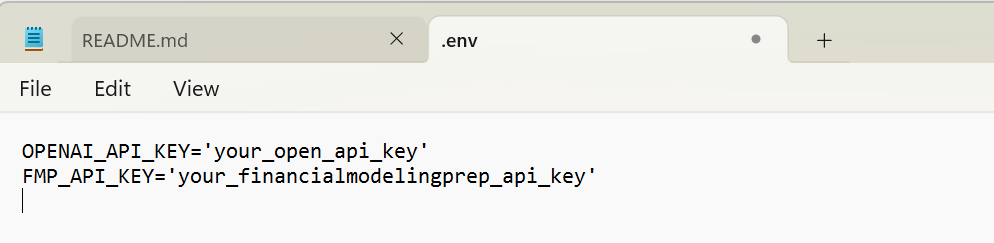
- Run the Streamlit app by executing:
streamlit run main.pyNote: Using a dockerized container to deploy this app requires about 200 MB more in terms of RAM
-
Copy the
Dockerfileand.envfile to the same folder on your local machine. -
Open PowerShell (or your preferred terminal) and navigate to this folder:
cd path_to_your_folder- Build the Docker image using the following command:
docker build -t finragify_app:latest .Note: Ensure that you have docker (docker desktop for Windows) installed and running before using docker commands
- Once the Docker image is created, run the Docker container by mapping the exposed port
8501(see the dockerfile) to an available port on your local machine (e.g.,8501,8502,8503):
docker run -d -p 8503:8501 --name finragify_container finragify_app:latest #this maps 8503 of local machine to exposed port 8501 of the app- Access the Streamlit app by navigating to
http://localhost:8503(or the port you've mapped) in your web browser.
If you prefer to deploy this application on an AWS EC2 instance, you can follow the general EC2 Streamlit app deployment steps mentioned in my previous README for another app here.