IDL Reference
Follow the same rules as in C/C++. Identifiers must start with an alphabetic character or underscore, and may include alphanumeric characters and underscores.
The following literal values are supported:
- Integer: Decimal (base 10) is the default. Hex values are prefixed with '0x' and binary values are prefixed with '0b'. Integer literals may be suffixed with 'u', 'ul', or 'ull', and are case-insensitive.
- Floating point: A decimal point prefixed and/or suffixed by decimal character sequences. The decimal point is required to form a floating point value. The optional exponent follows with no extra whitespace, consists of an 'e' or 'E', optional +/-, and a decimal sequence.
- Strings: are contained in double quotes. The usual escape sequences that begun with a backslash are supported, as well as hex character escapes such as "\x7d". Multiple consecutive string literals are accepted anywhere a string is valid in the grammar, and are concatenated into a single string.
All whitespace is ignored in the input file.
An expression is accepted in any place where an integer or floating point value is required.
| Operator | Function | Operator | Function |
|---|---|---|---|
| + | addition | ^ | binary XOR |
| - | subtraction | << | left shift |
| * | multiplication | >> | right shift |
| / | division | ||
| % | modulo | + | no-op (unary operator) |
| & | binary AND | - | negate (unary operator) |
| | | binary OR | ~ | binary inverse (unary operator) |
The usual precedence rules apply. Sub-expressions may be placed in parentheses ( ) to override normal precedence rules.
Another IDL file can be included in the parse by using the import keyword.
Prototype:
import stringThe string contains just the name, or the name-contained file path to the IDL file. The file path is relative to the base IDL file, or the file path could be relative to the given path to the eRPC generator.
Annotations provide a way to inform the eRPC generator about specific requests for some parts of the code.
- Unrecognized annotations are ignored by code generators.
- Each annotation starts with the “
@” character. - Then optionally can be inserted program language specifier followed with colon “
c:”. Currently supported program language specifiers arec( for C),py( for Python). Do not use with function/interface id annotation. - Then it is followed by the annotation name; for example,
@external.
This is enough for one type of annotation (when you want to only inform the eRPC generator about a specific attribute of the code). The second type of annotation is extended using the “( )” parentheses. A specific parameter can be placed inside parentheses. This can be a number, text, or other things.
When this annotation is used, then crc value is generated based on eRPC version and IDL file. User can access this value through extern const uint32_t erpc_generated_crc;. This value can be then set to eRPC tranport. Thanks to this transport checks if client and server have same eRPC version and IDL files without adding any execution code. Project need include "erpc_crc16.h" header file.
When non-encapsulated unions are used, discriminator needs be specified with using this annotation.
When the annotation @error_return is set, then this _value _ is used for the return value from the client-side called function, when the error will occur inside.
The @external annotation allows you to reference a type in an IDL file that already exists in another header file. In order for this to work, the type must be identically defined in the IDL file.
For example, if you have a typedef in a header file (typedef uint32_t erpc_status_t), and want to use this typedef, then define the type in your IDL file using the @external annotation: @external type erpc_status_t = uint32.
- This allows erpcgen to perform type checking when parsing the IDL file, but it will not generate any code for the type.
- This prevents duplicate definitions of the same type.
- This should work for all type definitions in an IDL file (struct, const, enum, typedef).
Interfaces can be grouped and stored in their set of output files via using @group annotation. String represent group name, which is used for output files. The file names look like: <fileName>_<groupName>.
| Filename | Description |
|---|---|
| <outputFileName>_<groupName>.h | Common header file for group |
| <outputFileName>_<groupName>_client.cpp | Client shim implementation for group |
| <outputFileName>_<groupName>_server.h | Server side header for group |
| <outputFileName>_<groupName>_server.cpp | Server shim implementation for group |
Annotation @id set interface/function id number. The number must be unique for each interface/function.
The string value represents the header file to include.
This annotation set reference for length variable. This can be either a number or variable. This prevents from wrapping list and binary data types to structure. Instead of structure, these data types are present as pointer to the element type. The length of pointer variable depends on value.
Annotation @max_length sets the maximum size of the string value. This size need be allocated by the client. This annotation simply informs the server how big of a space should be allocated to working with this variable. For example, when the variable is used as the inout type and the server needs to send back a bigger string, then the client sends it to them.
Annotation @name sets data type, function's param or structure's member name. This is invented for cases when the erpcgen is complaining about using IDL's reserved words, but for selected output programming language these are not reserved words.
Generated files have a default-enabled generating error checking code for catching errors from bad allocations. For disabling generating errors checking code for bad allocation just add @no_alloc_errors.
When this annotation is set to program, then no "const" word are generated for functions parameters. This can be used also for function or parameter.
Generated files have a default-enabled generating error checking code for catching errors from codec functions. For disabling generating errors checking code from codec, just add @no_infra_errors annotation.
Annotation @nullable informs shim code that variables can be set to NULL. Without this annotation, the variable (passed by client, or returned from the server function implementation) cannot be NULL.
String value that represents the output path. The output directory can also be set as a command line option for the eRPC generator. When @output_dir(string) and the eRPC generator command line option are both used, the path from the IDL file is appended to the path given to the eRPC generator.
Annotation @retain prevents the server to call freeing functions on variables, which are used in server function implementation.
When this annotation is set to function's parameter or structure's member, then data are not serialized, just an address to data. This can be used in multicore system with shared memory pool.
This annotation sets begin address of shared memory. When this is used generated code controls if given address is from this memory pool.
This annotation sets end address of shared memory. When this is used generated code controls if given address is from this memory pool.
All type declarations (for example typedef and struct) will be moved into the defined header file. This prevents duplicate definition errors when using @group.
The optional program statement is used to specify the name of the input as a whole. This name is used for the output file name.
program some_program_nameThe program statement does not cause any code to generate by itself. It is used both for documentation purposes and as an anchor point to which annotations may be attached. Annotations must be placed before the program statement.
@crc
@dynamic_services
@include(string)
@no_alloc_errors
@no_const_param
@no_infra_errors
@output_dir(string)
@shared_memory_begin(value)
@shared_memory_end(value)
@types_header
The interface contains one or more functions, which are called on the client side. The implementations are written on the server side.
Prototype:
interface _interfaceName_ {}Interfaces also generate one more special function. Because generated functions are written as C++ functions (they use classes), C-users generate C-function create_<interfaceName>_service(). This function should be the call function.
Supported annotations are used before a interface declaration.
@group(string)
@id(number)
@include(string)
@name(string)
Functions are called by the client, and the implementations are written on the server side. There are two supported IDL function declarations:
oneway function()The oneway function should be used when no return message is expected.
function() -> returnDataTypeThis function should be used when a return message is expected (for example, the returning value). The difference between using the oneway and void is that the void function waits for a response from the server side.
Attributes are placed inside parentheses ( ), similar to how it is done in C-functions (using the supported IDL data types).
Supported annotations are used before a function declaration.
@error_return(value)
@external
@id(number)
@name(string)
@no_const_param
Parameters annotations are set after parameter name. Supported annotations are described for each data type in chapters bellow. Prototype:
function(string a @max_length(10), list<int32> b @length(c), int32 c) -> @nullable list<int32>These are the built-in, atomic, scalar, complex types supported by erpcgen. These types are mostly self-explanatory.
@external
@name(string)
@no_const_param
@shared
The IDL type representation for this is: type _aliasName_ = _originalType_
| IDL definition | C definition |
|---|---|
| type aliasName = int32 | typedef int32_t aliasName; |
| type aliasName = list | typedef list_int32_1_t aliasName; |
| type aliasName = int32[20] | typedef int32_t aliasName[20]; |
The built-in atomic types convert to standard integer types. The string type converts directly to a char*.
| IDL definition | C definition | Java definition | IDL definition | C definition | Java definition |
|---|---|---|---|---|---|
| bool | bool | Boolean | uint8 | uint8_t | short* |
| int8 | int8_t | byte | uint16 | uint16_t | int* |
| int16 | int16_t | short | uint32 | uint32_t | long* |
| int32 | int32_t | int | uint64 | uint64_t | Unsupported |
| int64 | int64_t | long | float | float | float |
| string | char* | String | double | double | double |
| *Java uses larger data types to store unsigned numbers, verifying their range during encoding and decoding. |
The string length is determined by the terminating null byte, which means that no null characters may be included in the middle of the string. The major impact of this is that UTF-8 is not fully supported. If the arbitrary UTF-8 text is intended to be transferred, then the binary type must be used.
@max_length(value)
@nullable
@retain
As default the binary type generates a C-type equivalent to list<uint8>. The differences between binary type and list type are:
- Binary data type is handled far more efficiently when serializing and deserializing.
- Binary type has different names of structure members.
typedef struct binary_t binary_t;
struct binary_t {
int8_t *data;
uint32_t dataLength;
};@length(value)
@max_length(value)
@retain
Enumerations in the IDL input generate matching enumeration definitions in C. The only difference is that constant expressions are evaluated in the output. Additionally, a typedef with a matching name is generated.
enum enumColor {
red,
green = 10,
blue = 2 * 10
}typedef enum enumColor {
red,
green = 10,
blue = 20
} enumColor;public enum enumColor{
red(1),
green(10),
blue(20);
public int getValue() { ... }
public static enumColor get(int value) { ... }
}@name(string)
Structures are created with an implicit typedef for the name provided in the IDL file. When "byref" keyword is used in front of structure's member declaration, then structure's member is serialized through reference.
struct A {
int32 a
byref float b
}typedef struct A A;
struct A {
int32_t a;
float *b;
};Two helper functions are generated for encoding and decoding structures. The prototypes for such functions are:
int32_t read_<struct_typename>_struct(erpc::Codec * in, <struct_typename> * data);int32_t write_<struct_typename>_struct(erpc::Codec * out, <struct_typename> * data);
For all functions that either return a structure or pass a structure as a parameter, those functions expect a pointer to the structure type.
public class A{
private int a;
private Reference<Float> b;
public A (int a, Reference<Float> b) {
this.a = a;
this.b = b;
}
public A() {
}
public int get_a() { ... }
public void set_a(int a) { ... }
public Reference<Float> get_b() { ... }
public void set_b(Reference<Float> b) { ... }
}@name(string)
@nullable
@retain
A discriminated union allows a user to create a kind of variant object, thereby allowing a user to send or return data of different types. The definition of a discriminated union in the IDL file uses a switch-statement-like syntax to define which union member is valid for the corresponding discriminator value. The eRPC is recognizing two types of discriminated unions:
1. Non-encapsulated union: A definition of union type is placed in global scope. A discriminator needs be defined through annotation @discriminator(disriminator_name).
enum enumType{ A, B, C, D, E, F }
union unionType
{
case A:
int32 a
case B:
float b
case C:
case D, E:
list<int32> c
case F:
int32 x
int32 y
default:
int32 z
}
struct A
{
int32 discriminator;
unionType data @discriminator(discriminator);
}enum enumType
{
A=1,
B=2,
C=3,
D=4,
E=5,
F=6
}enumType;
typedef union unionType unionType;
typedef struct A A;
union unionType
{
int32_t a;
float b;
list_int32_1_t c;
struct {
int32_t x;
int32_t y;
};
int32_t z;
};
struct A {
int32_t discriminator;
unionType data;
};@discriminator
@name(string)
@nullable
@retain
2. Encapsulated unions: A definition of union type is part of a structure with one or more scalar types, one or more unions, and any other necessary data members for the struct. A discriminator is presented as member of current structure.
enum { A, B, C, D, E, F }
struct A {
int32 discriminator
union(discriminator)
{
case A:
int32 a
case B:
float b
case C:
case D, E:
list<int32> c
case F:
int32 x
int32 y
default:
int32 z
} data
}enum enumType
{
A=1,
B=2,
C=3,
D=4,
E=5,
F=6
}enumType;
typedef struct A A;
struct A {
int32_t discriminator;
union
{
int32_t a;
float b;
list_int32_1_t c;
struct {
int32_t x;
int32_t y;
};
int32_t z;
} data;
};@name(string)
Discriminated unions have a few special features:
- As shown for cases C, D, and E, you can assign the same union member to multiple discriminator values, either by allowing case definitions to fall through, or by providing a list of discriminator values within a single case.
- Case F shows that discriminated unions also allow generation of anonymous structs within the union.
- There is also the ‘default’ case, which is invoked if the discriminator value is set to something not defined explicitly by one of the union cases within the IDL.
The IDL type representation for this type is list<typename>.
Because the C language does not have a built-in list type, the generator must synthesize one (a list type) when generating code. This is done by combining an array pointer with a list element count in a structure. Each unique list type specified in the IDL causes a new structure type to be defined.
The conversion is very straightforward. For list<int32>, this code is generated:
struct list_int32_1_t {
int32_t * elements;
uint32_t elementsCount;
};Type definitions for the list structures are generated in a separate forward declarations section of the output file.
For simplicity, the names of the synthesized list structures are currently set to "list_x_y_t", where x is base type and y is a unique integer. It is recommended to create a type alias to define a user-friendly name for the list structure. The issue is that the list structure names that include an element type description could potentially become excessively long.
Java use interface List<T> as default list type. Server side use ArrayList<>() as default implementation of the
List<T>. It is possible to use any implementation of List<T>.
@length
@max_length
@nullable
@retain
The IDL type representation for this type is typeName[N] variableName, where N is an integer constant expression.
| IDL definition | C definition | Java definition |
|---|---|---|
| int32[10] variable | int32_t variable[10]; | int[] variable = new int[10]; |
| int32[10][6] variable | int32_t variable[10][6]; | int[][] variable = new int[10][6]; |
functionName(int [8][10] a) -> int [8][4]int * (functionName(int32_t a[8][10]))[8][4];@retain
Callback is another name of the function data type. This data type can be used as others' data types. This data type is intended for sending the function reference through eRPC call to the second side. The second side can then be the executed real function. The Callback type is declared outside of the interface. The Callback function is declared inside interface. The Callback function is regular eRPC function, which the address can be passed to the another eRPC function as a parameter value.
oneway callback1_t(int32 a, int32 b)
interface Core0Interface
{
oneway myFun(in callback1_t pCallback1_t)
@include("callbacks1.h")
callback1_t callback1; // Function declaration
}typedef void (*callback1_t)(int32_t a, int32_t b);
void myFun(const callback1_t pCallback1_t);
void callback1(int32_t a, int32_t b);@no_const_param
@nullable
The IDL supports declarations of constants. These constants are replicated in the generated output. Constants are defined with the const keyword. They look just like the constant global variables in C, and include a type and name (in that order).
String constant prototype: const string kVersion = stringValue
Java stores all constants in class common.Constants.
Supported keywords for parameter directions are: in, out, and inout. These keywords are used to specify the parameter direction type. The direction keywords are placed before the parameter type. If the direction for a parameter is not specified, then it is the in direction.
For example: void function(out int32 param)
The next figure shows who is sending and who is receiving the parameter value.
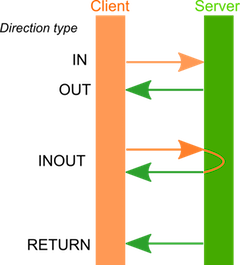
How memory allocations are provided depends on the type of application:
- On client-side applications: all memory allocations have to be provided by user code.
- On server-side applications: all memory allocations are provided by server shim code. The user cannot change the memory allocation provided by the shim code.
The next table shows how data types are translated from IDL to C as function parameters.
| Data type | in | out | inout | Returns |
|---|---|---|---|---|
| Built-in types | int32 param | int32 *param | int32 *param | int32 |
| string | char *param | char *param | char *param | Not supported |
| enum | B param | B *param | B *param | B |
| struct | const A *param | A *param | A *param | Not supported |
| list | const list_int32_1_t *param | list_int32_1_t *param | list_int32_1_t *param | Not supported |
| array | const int32 param[5] | int32 param[5] | int32 param[5] | Not supported |
If a type definition is used, then all pointers are generated as shown in the two previous tables. Instead of these types, the type definition name is used.
The variable needs to have a set annotation to work for some cases. For example, out string need set , and @max_length`` annotation inform the server the how much memory space needs to be allocated for the string. This size should be allocated by the client on the client side, and is filled by shim code.
Java use Reference<T> for out and inout parameters. Reference<T> has two methods public T get() {} and public void set(T newVal) {}.
- On the client side: All memory space has to be allocated and provided by the user code. The shim code only reads from or writes into this memory space.
- On the server side: All memory space is allocated and provided by the shim code. The user code only reads from or writes into this memory space.
When the client uses a list data type, the code has to allocate space for the elements and put the number of elements in elementsCount. The client can set elementsCount to “0”.
There are two types of comments:
Are //sometext or /* sometext */. These can be used everywhere within the IDL file, but these comments are not copied into the generated output file.
Are copied into the generated output header file. Doxygen comments can be placed before a declaration, and look like the following:
/*! sometext */
/** sometext */
/// sometext
//! sometextTrailing Doxygen comments are placed after:
- member declaration
- name for structure
- name for enumeration
- name for interface
- constant declaration
- function declaration
and they look like the following:
/*!< sometext */
/**< sometext */
///< sometext
//!< sometext