由一个字符串变为另一个字符串的最少操作次数,可以删除一个字符,替换一个字符,插入一个字符,也叫做最小编辑距离。
我们可以发现删除一个字符和插入一个字符是等效的,对于变换次数并没有影响。例如 "a" 和 "ab" ,既可以 "a" 加上一个字符 "b" 变成 "ab",也可以是 "ab" 去掉一个字符 "b" 变成 "a"。所以下边的算法可以只考虑删除和替换。
首先,以递归的思想去考虑问题,思考如何将大问题化解为小问题。例如 horse 变为 ros,其实我们有三种可选方案。
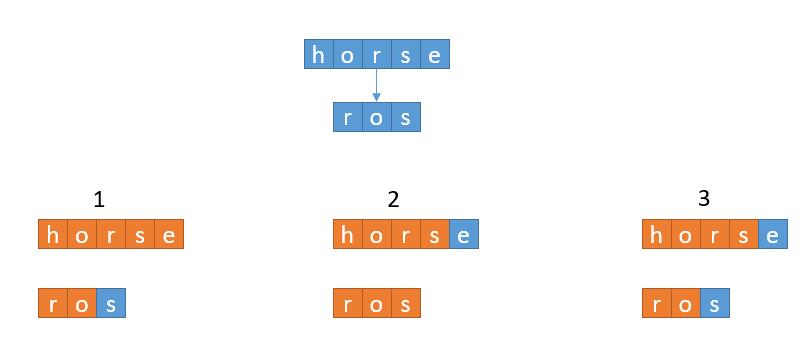
第一种,先把 horse 变为 ro ,求出它的最短编辑距离,假如是 x,然后 hosre 变成 ros 的编辑距离就可以是 x + 1。因为 horse 已经变成了 ro,然后我们可以把 ros 的 s 去掉,两个字符串就一样了,也就是再进行一次删除操作,所以加 1。
第二种,先把 hors 变为 ros,求出它的最短编辑距离,假如是 y,然后 hosre 变成 ros 的编辑距离就可以是 y + 1。因为 hors 变成了 ros,然后我们可以把 horse 的 e 去掉,两个字符串就一样了,也就是再进行一次删除操作,所以加 1。
第三种,先把 hors 变为 ro,求出它的最短编辑距离,假如是 z,然后我们再把 e 换成 s,两个字符串就一样了,hosre 变成 ros 的编辑距离就可以是 z + 1。当然,如果是其它的例子,最后一个字符是一样的,比如是 hosrs 和 ros ,此时我们直接取 z 作为编辑距离就可以了。
最后,我们从上边所有可选的编辑距离中,选一个最小的就可以了。
上边的第一种情况,假设了 horse 变为 ro 的最短编辑距离是 x,但其实我们并不知道 x 是多少,这个怎么求呢?类似的思路,也分为三种情况,然后选最小的就可以了!当然,上边的第二种,第三种情况也是类似的。然后一直递归下去。
最后,字符串长度不断地减少,直到出现了空串,这也是我们的递归出口了,如果是一个空串,一个不是空串,假如它的长度是 l,那么这两个字符串的最小编辑距离就是 l。如果是两个空串,那么最小编辑距离当然就是 0 了。
上边的分析,很容易就写出递归的写法了。
public int minDistance(String word1, String word2) {
if (word1.length() == 0 && word2.length() == 0) {
return 0;
}
if (word1.length() == 0) {
return word2.length();
}
if (word2.length() == 0) {
return word1.length();
}
int x = minDistance(word1, word2.substring(0, word2.length() - 1)) + 1;
int y = minDistance(word1.substring(0, word1.length() - 1), word2) + 1;
int z = minDistance(word1.substring(0, word1.length() - 1), word2.substring(0, word2.length() - 1));
if(word1.charAt(word1.length()-1)!=word2.charAt(word2.length()-1)){
z++;
}
return Math.min(Math.min(x, y), z);
}上边的算法缺点很明显,先进行了压栈,浪费了很多时间,其次很多字符串的最小编辑距离都进行了重复计算。对于这种,很容易想到动态规划的思想去优化。
假设两个字符串是 word1 和 word2。
ans[i][j] 来表示字符串 word1[ 0, i ) (word1 的第 0 到 第 i - 1个字符)和 word2[ 0, j - 1) 的最小编辑距离。然后状态转移方程就出来了。
if ( word1[m] == word2[n] )
ans[m][n] = Math.min ( ans[m][n-1] + 1, ans[m-1][n] + 1, ans[m-1][n-1])
if ( word1[m] != word2[n] )
ans[m][n] = Math.min ( ans[m][n-1] + 1, ans[m-1][n] + 1, ans[m-1][n-1] + 1)
然后两层 for 循环,直接一层一层的更新数组就够了。
public int minDistance(String word1, String word2) {
if (word1.length() == 0 && word2.length() == 0) {
return 0;
}
if (word1.length() == 0) {
return word2.length();
}
if (word2.length() == 0) {
return word1.length();
}
int[][] ans = new int[word1.length() + 1][word2.length() + 1];
//把有空串的情况更新了
for (int i = 0; i <= word1.length(); i++) {
ans[i][0] = i;
}
for (int i = 0; i <= word2.length(); i++) {
ans[0][i] = i;
}
int n1 = word1.length();
int n2 = word2.length();
//从 1 开始遍历,从 0 开始的话,按照下边的算法取了 i - 1 会越界
for (int i = 1; i <= n1; i++) {
for (int j = 1; j <= n2; j++) {
int min_delete = Math.min(ans[i - 1][j], ans[i][j - 1]) + 1;
int replace = ans[i - 1][j - 1];
if (word1.charAt(i - 1) != word2.charAt(j - 1)) {
replace++;
}
ans[i][j] = Math.min(min_delete, replace);
}
}
return ans[n1][n2];
}时间复杂度:O(mn)。
空间复杂度:O(mn)。
如果你是顺序刷题的话,做到这里,一定会想到空间复杂度的优化,例如5题,10题,53题等等。主要想法是,看上边的算法,我们再求 ans[i][*] 的时候,我们只用到 ans[i - 1][*] 的情况,所以我们完全只用两个数组就够了。
public int minDistance(String word1, String word2) {
if (word1.length() == 0 && word2.length() == 0) {
return 0;
}
if (word1.length() == 0) {
return word2.length();
}
if (word2.length() == 0) {
return word1.length();
}
int[][] ans = new int[2][word2.length() + 1];
for (int i = 0; i <= word2.length(); i++) {
ans[0][i] = i;
}
int n1 = word1.length();
int n2 = word2.length();
for (int i = 1; i <= n1; i++) {
//由于只用了两个数组,所以不能向以前一样一次性初始化空串,在这里提前更新 j = 0 的情况
ans[i % 2][0] = ans[(i - 1) % 2][0] + 1;
for (int j = 1; j <= n2; j++) {
int min_delete = Math.min(ans[(i - 1) % 2][j], ans[i % 2][j - 1]) + 1;
int replace = ans[(i - 1) % 2][j - 1];
if (word1.charAt(i - 1) != word2.charAt(j - 1)) {
replace++;
}
ans[i % 2][j] = Math.min(min_delete, replace);
}
}
return ans[n1 % 2][n2];
}时间复杂度:O(mn)。
空间复杂度:O(n)。
再直接点,其实连两个数组我们都不需要,只需要一个数组。改写这个可能有些不好理解,可以结合一下图示。
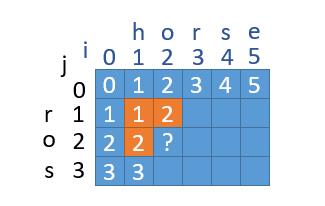
在更新二维数组的时候,我们都是一列一列的更新。在更新 ? 位置的时候,我们需要橙色位置的信息,也就是当前列的上一个位置,和上一列的当前位置,和上一列的上一个位置。如果我们用一个数组,当前列的上一个位置已经把上一列的上一个位置的数据覆盖掉了,所以我们要用一个变量提前保存上一列的上一个位置以便使用。
public int minDistance(String word1, String word2) {
if (word1.length() == 0 && word2.length() == 0) {
return 0;
}
if (word1.length() == 0) {
return word2.length();
}
if (word2.length() == 0) {
return word1.length();
}
int[] ans = new int[word2.length() + 1];
for (int i = 0; i <= word2.length(); i++) {
ans[i] = i;
}
int n1 = word1.length();
int n2 = word2.length();
for (int i = 1; i <= n1; i++) {
int temp = ans[0];
ans[0] = ans[0] + 1;
for (int j = 1; j <= n2; j++) {
int min_delete = Math.min(ans[j], ans[j - 1]) + 1;
//上一列的上一个位置,直接用 temp
int replace = temp;
if (word1.charAt(i - 1) != word2.charAt(j - 1)) {
replace++;
}
//保存当前列的信息
temp = ans[j];
//再进行更新
ans[j] = Math.min(min_delete, replace);
}
}
return ans[n2];
}时间复杂度:O(mn)。
空间复杂度:O(n)。
动态规划的一系列操作,先递归,利用动态规划省略压栈的过程,然后空间复杂度的优化,很经典了。此外,对于动态规划数组的含义的定义也是很重要,开始的时候自己将 ans[i][j] 表示为 字符串 word1[ 0, i ](word1 的第 0 到 第 i 个字符)和 word2[ 0, j - 1] 的最小编辑距离。和上边解法的区别只是包含了末尾的字符。这造成了初始化 ans[0][*] 和 ans[*][0] 的时候,会比较复杂,看到了这里的解法,才有一种柳暗花明的感觉,思路是一样的,但更新ans[0][*] 和 ans[*][0] 却简单了很多。