Operational credit mining branch, Gumby scenario and multichain #1842
Comments
Thesis Proposal/Roadmap v.0.3Big goal :
Benefit :
Current state of the art :
Some definitions :
What is credit :
Specific Task (no specific order) :
Problem/Limitation/Doubt :
Related work :
|
|
This is my current progress https://github.com/ardhipoetra/tribler/commits/credit_mining |
|
Concrete ToDo:
Next step: torrent_checker.py integration. |
|
Initial GUI on Tribler home screen: Credit mining screen: 1000+ discovered channels, overall credit mining dashboard, channel status, channel content status. Thesis storyline:
Next sprint: accurate investment information, torrent_checker.py integration, discovered swarms, downloaded torrents, DHT lookup failure, failed to download .torrent, used bandwidth for checking, swarms connected to, dead swarms, seeder/leecher info determined. |


|
Next steps: understand swarm seed/leecher checking. Running code to bypass central tracker. Also problem to TCP check trackers, as tunnels only support UDP. Goal: create a good scrape mechanism using DHT and UDP in existing messy Tribler code. Some very old code is still using manual checking in our own Python code: Now we use Libtorrent, which has it's own DHT and another DHT library: pymdht. |
|
The more recent versions of libtorrent have exposed more stuff to the python bindings. It would be nice if someone checked if the needed DHT stuff is available now. That would allow us to drop pymdht entirely. |
|
Completed:
Tasks for coming 3 weeks:
Thesis material credit
Leftover work:
|
|
additional thesis material: |
|
working code, see issues above. Create a legal channel with 500+ legal swarms. Repeat the Mihai experiments. Show in Gumby on Jenkins with nice R plots. |
|
Elric has 300 swarm and we have legal swarms from archive.org Another legal source: http://terasaur.org/browse/category/video |
|
Focus for 2 weeks: finish Problem Description and Related work (in 2 chapters or 1):
ToDo:
|
|
Thesis latex repository : https://github.com/ardhipoetra/msc-thesis-creditmining |
|
Create:
October steps: experiments with prospecting: select channel, DHT responsiveness, time to download download first 4 pieces, discovered swarm size (PEX,seed/leech stats). |
|
Problem description revision : 2.5 : how to prospect a good investment 2.6 : when to delete a downloaded swarm and replace it with a new investment |
|
Thesis feedback :
ToDo: pull requests ! |
|
It has been processed in ardhipoetra/msc-thesis-creditmining@04ce285. For prospecting details (how it works), I want to put that on 'design' chapter. |
|
Downloading 4 pieces of 10k+ torrents in 12 hours with 500 torrent connection in one time, timeout is 1 hour, resulting in below :
|


|
Gumby repository, with current experiments : https://github.com/ardhipoetra/gumby/tree/credit_mining_exp/experiments/credit_mining |
|
Idea for final experiment (after discussing prospecting) :
Next sprint:
With progress: create thesis committee |
|
idea for 1st experiment of thesis. This first experiment is designed to evaluate the basic operation, correctness, responsiveness, and efficiency of our work. It is specifically crafted to be simple and easy to understand plus debug. 1 channel, add torrent, add 1 credit miner. Add second torrent, measure how fast it is mined.. |
|
@EinNarr Just talked to Johan about your experiments, and you're very much invited to compare multiple policies in your thesis. The torrents in your experiment can just be synthetic. No need to use wild swarms. This avoids your problems with many overseeded swarms. |
|
Explore different parameter settings & experiments:
|
|
One of the Gumby scenario files: https://github.com/ardhipoetra/gumby/blob/0f860dcad94a59324b1a80d946977b4344731fb3/experiments/tribler/channel_download.scenario You can check out this PR: Tribler/gumby#282 |
|
Roadmap to graduation still remains unclear. |
|
Experiments done outside Tribler till now.
|








|
Some thoughts about the 4th policy. It could be that no torrent is ever super-promoted, or only small torrents less than 120MB are super-promoted. |


|
Very impressive thesis material! |
|
Please focus on your thesis writing and storyline now. Stop working on graphs and data processing. We present in this chapter the experiments we conducted around credit mining investments with the following scientific topics:
|
|
Another latest version of PDF and an interesting percentage change of total download of each category. |

|
|
Plus this remark: "the link to his code added to the thesis (in the spirit of reproducibility)." |
Thesis is still not clearThesis is not in good shape yet sadly. Detailed remarks:
|
|
|
Summary of suggested changes after a discussion between Przemyslaw Pawelczak and Bohao Zhang on 28 September 2018, 10:30 TU Delft Content corrections:
Text structure corrections:
Editorial corrections:
|
|
Related work on Delft University credit mining:
|
|
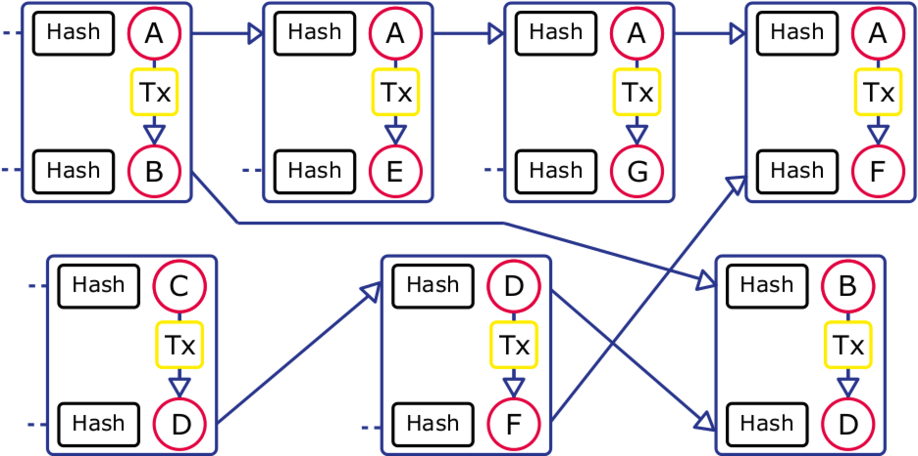
A live screenshot of token mining running multi-level policy |

{kind=link}
{kind=link}
|
After years of effort, we finally have an operational credit mining strategy. Now it actually generates tokens as well 😃 |
Get a working performance analysis environment.
Goal: ability to make pretty graphs locally with both credit mining and multichain (two different branches).
Task: make an Ubuntu channel or other large validated legal collection, with actual "from the wild" downloads.
This environment will be expanded over coming months.
part of #23.
ToDo: read "tragedy of the commons" paper, 1968 problem.
Strategy: Till end of Feb focus on credit mining, then include relaying bandwidth to avoid too much complexity at the start.
Next sprint: co-investor detection?
The text was updated successfully, but these errors were encountered: